TypeScript 项目中 PlanetScale 的内省
使用 Prisma ORM 内省您的数据库
为本指南的目的,我们将使用一个包含三个表的演示 SQL Schema
CREATE TABLE `Post` (
`id` int NOT NULL AUTO_INCREMENT,
`createdAt` datetime(3) NOT NULL DEFAULT CURRENT_TIMESTAMP(3),
`updatedAt` datetime(3) NOT NULL,
`title` varchar(255) COLLATE utf8mb4_unicode_ci NOT NULL,
`content` varchar(191) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`published` tinyint(1) NOT NULL DEFAULT '0',
`authorId` int NOT NULL,
PRIMARY KEY (`id`),
KEY `Post_authorId_idx` (`authorId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `Profile` (
`id` int NOT NULL AUTO_INCREMENT,
`bio` varchar(191) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
`userId` int NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `Profile_userId_key` (`userId`),
KEY `Profile_userId_idx` (`userId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
CREATE TABLE `User` (
`id` int NOT NULL AUTO_INCREMENT,
`email` varchar(191) COLLATE utf8mb4_unicode_ci NOT NULL,
`name` varchar(191) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `User_email_key` (`email`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
展开以查看表的图形概览
Post
| 列名 | 类型 | 主键 | 外键 | 必需 | 默认值 |
|---|---|---|---|---|---|
id | int | ✔️ | 否 | ✔️ | 自增 |
createdAt | datetime(3) | 否 | 否 | ✔️ | now() |
updatedAt | datetime(3) | 否 | 否 | ✔️ | |
title | varchar(255) | 否 | 否 | ✔️ | - |
content | varchar(191) | 否 | 否 | 否 | - |
published | tinyint(1) | 否 | 否 | ✔️ | false |
authorId | int | 否 | 否 | ✔️ | - |
Profile
| 列名 | 类型 | 主键 | 外键 | 必需 | 默认值 |
|---|---|---|---|---|---|
id | int | ✔️ | 否 | ✔️ | 自增 |
bio | varchar(191) | 否 | 否 | 否 | - |
userId | int | 否 | 否 | ✔️ | - |
User
| 列名 | 类型 | 主键 | 外键 | 必需 | 默认值 |
|---|---|---|---|---|---|
id | int | ✔️ | 否 | ✔️ | 自增 |
name | varchar(191) | 否 | 否 | 否 | - |
email | varchar(191) | 否 | 否 | ✔️ | - |
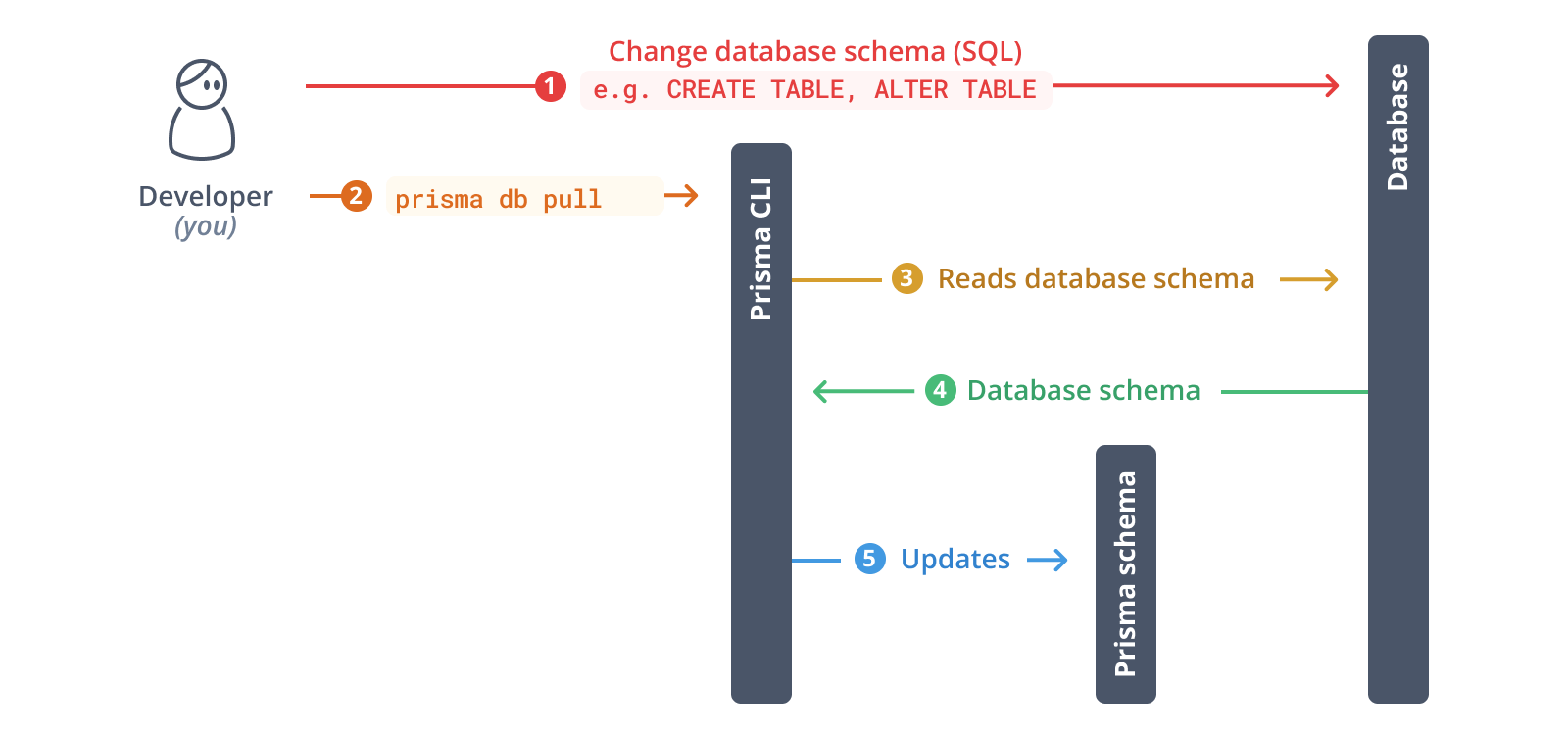
下一步,您将内省您的数据库。内省的结果将在您的 Prisma Schema 中生成一个数据模型。
运行以下命令来内省您的数据库
npx prisma db pull
此命令读取 `.env` 中定义的 `DATABASE_URL` 环境变量并连接到您的数据库。建立连接后,它将内省数据库(即*读取数据库 Schema*)。然后,它将数据库 Schema 从 SQL 转换为 Prisma 数据模型。
内省完成后,您的 Prisma Schema 将被更新
数据模型现在看起来类似于这样
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime
title String @db.VarChar(255)
content String?
published Boolean @default(false)
authorId Int
@@index([authorId])
}
model Profile {
id Int @id @default(autoincrement())
bio String?
userId Int @unique
@@index([userId])
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
}
有关 Schema 定义的详细信息,请参阅Prisma Schema 参考。
Prisma 的数据模型是您的数据库 Schema 的声明性表示,并作为生成的 Prisma Client 库的基础。您的 Prisma Client 实例将公开*根据*这些模型*定制*的查询。
然后,您需要使用关系字段添加数据之间所有缺失的关系。
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime
title String @db.VarChar(255)
content String?
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
@@index([authorId])
}
model Profile {
id Int @id @default(autoincrement())
bio String?
user User @relation(fields: [userId], references: [id])
userId Int @unique
@@index([userId])
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
profile Profile?
}
在此之后,再次对您的数据库运行内省
npx prisma db pull
Prisma Migrate 现在将保留手动添加的关系字段。
由于关系字段是*虚拟的*(即它们*不会直接体现在数据库中*),您可以手动在 Prisma Schema 中重命名它们,而无需更改数据库。
在此示例中,数据库 Schema 遵循 Prisma ORM 模型的命名约定。这优化了生成的 Prisma Client API 的人体工程学。
使用自定义模型和字段名称
有时,您可能希望对 Prisma Client API 中公开的列和表的名称进行额外更改。一个常见示例是将数据库 Schema 中常用的*snake_case*(蛇形命名法)转换为对 JavaScript/TypeScript 开发者更自然的*PascalCase*(帕斯卡命名法)和*camelCase*(驼峰命名法)。
假设您通过内省获得了以下基于*snake_case*(蛇形命名法)的模型
model my_user {
user_id Int @id @default(autoincrement())
first_name String?
last_name String @unique
}
如果您为此模型生成 Prisma Client API,它将在其 API 中沿用*snake_case*(蛇形命名法)
const user = await prisma.my_user.create({
data: {
first_name: 'Alice',
last_name: 'Smith',
},
})
如果您不想在 Prisma Client API 中使用数据库的表和列名,您可以使用`@map` 和 `@@map` 来配置它们。
model MyUser {
userId Int @id @default(autoincrement()) @map("user_id")
firstName String? @map("first_name")
lastName String @unique @map("last_name")
@@map("my_user")
}
通过这种方法,您可以随意命名您的模型及其字段,并使用 `@map`(用于字段名)和 `@@map`(用于模型名)指向底层的表和列。您的 Prisma Client API 现在看起来如下
const user = await prisma.myUser.create({
data: {
firstName: 'Alice',
lastName: 'Smith',
},
})
有关更多信息,请访问配置您的 Prisma Client API 页面。