什么是内省?
您可以使用 Prisma CLI 对数据库进行内省,以在 Prisma schema 中生成数据模型。数据模型是生成 Prisma Client 所必需的。
将 Prisma ORM 添加到现有项目时,内省通常用于生成数据模型的初始版本。
但是,它也可以在应用程序中重复使用。当您不使用 Prisma Migrate 而是使用纯 SQL 或其他迁移工具执行 schema 迁移时,这种情况最常见。在这种情况下,您还需要重新内省数据库并随后重新生成 Prisma Client,以反映 Prisma Client API 中的 schema 更改。
内省的作用是什么?
内省有一个主要功能:用反映当前数据库 schema 的数据模型填充您的 Prisma schema。
以下是它在 SQL 数据库上的主要功能概述
- 将数据库中的表映射到Prisma 模型
- 将数据库中的列映射到 Prisma 模型的字段
- 将数据库中的索引映射到 Prisma schema 中的索引
- 将数据库约束映射到 Prisma schema 中的属性或类型修饰符
在 MongoDB 上,主要功能如下
- 将数据库中的集合映射到Prisma 模型。由于 MongoDB 中的集合没有预定义结构,Prisma ORM 会对集合中的文档进行采样并相应地推导模型结构(即,它将文档的字段映射到 Prisma 模型的字段)。如果在集合中检测到嵌入类型,这些将被映射到 Prisma schema 中的复合类型。
- 如果集合中至少有一个文档包含索引中包含的字段,则将数据库中的索引映射到 Prisma schema 中的索引
您可以在数据源连接器对应的文档页面上,了解 Prisma ORM 如何将数据库中的类型映射到 Prisma schema 中可用的类型
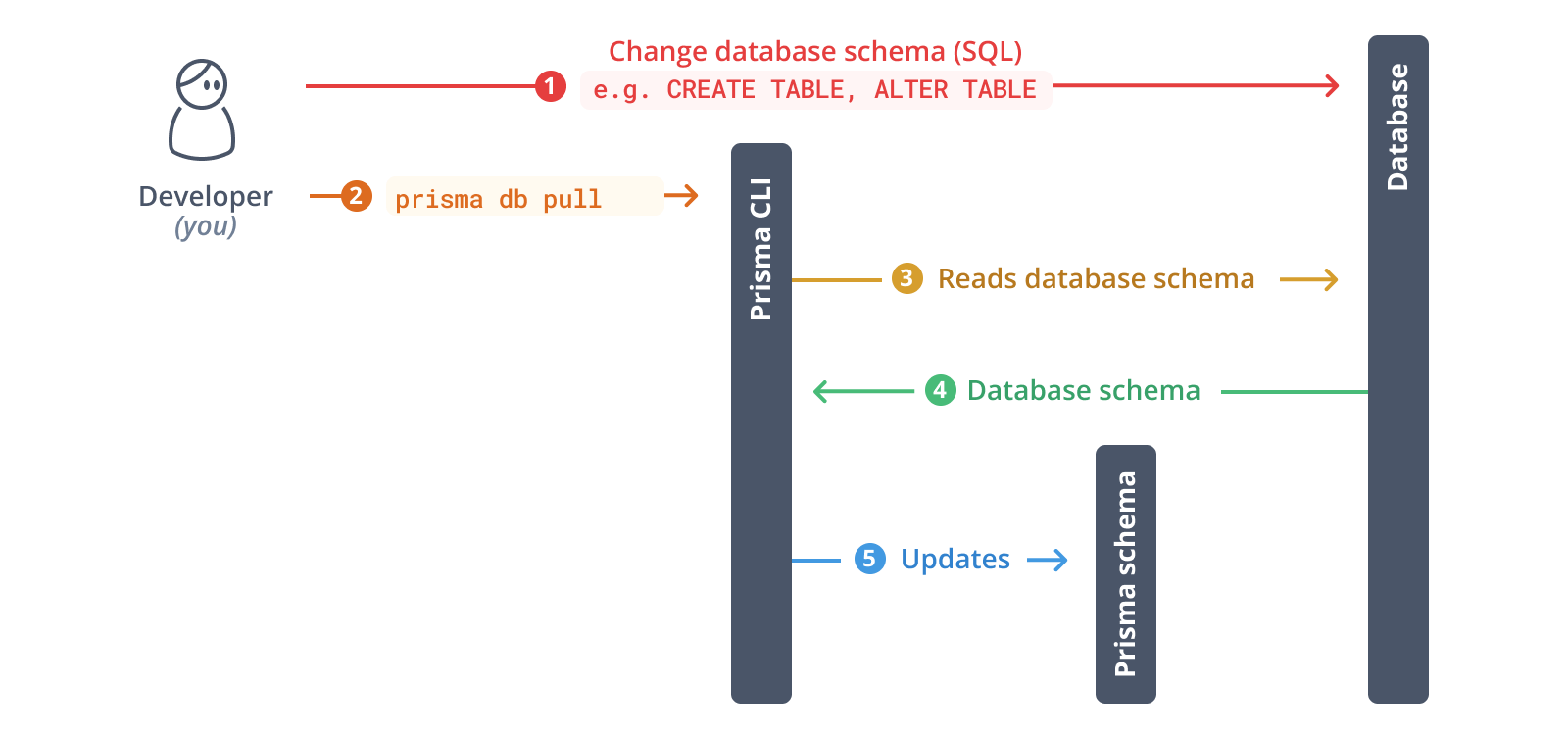
prisma db pull 命令
您可以使用 Prisma CLI 的 prisma db pull 命令对数据库进行内省。请注意,使用此命令需要在 Prisma schema datasource 中设置您的连接 URL。
以下是 prisma db pull 内部执行步骤的高级概述
- 从 Prisma schema 中的
datasource配置读取连接 URL - 打开数据库连接
- 内省数据库 schema(即读取表、列和其他结构...)
- 将数据库 schema 转换为 Prisma schema 数据模型
- 将数据模型写入 Prisma schema 或更新现有 schema
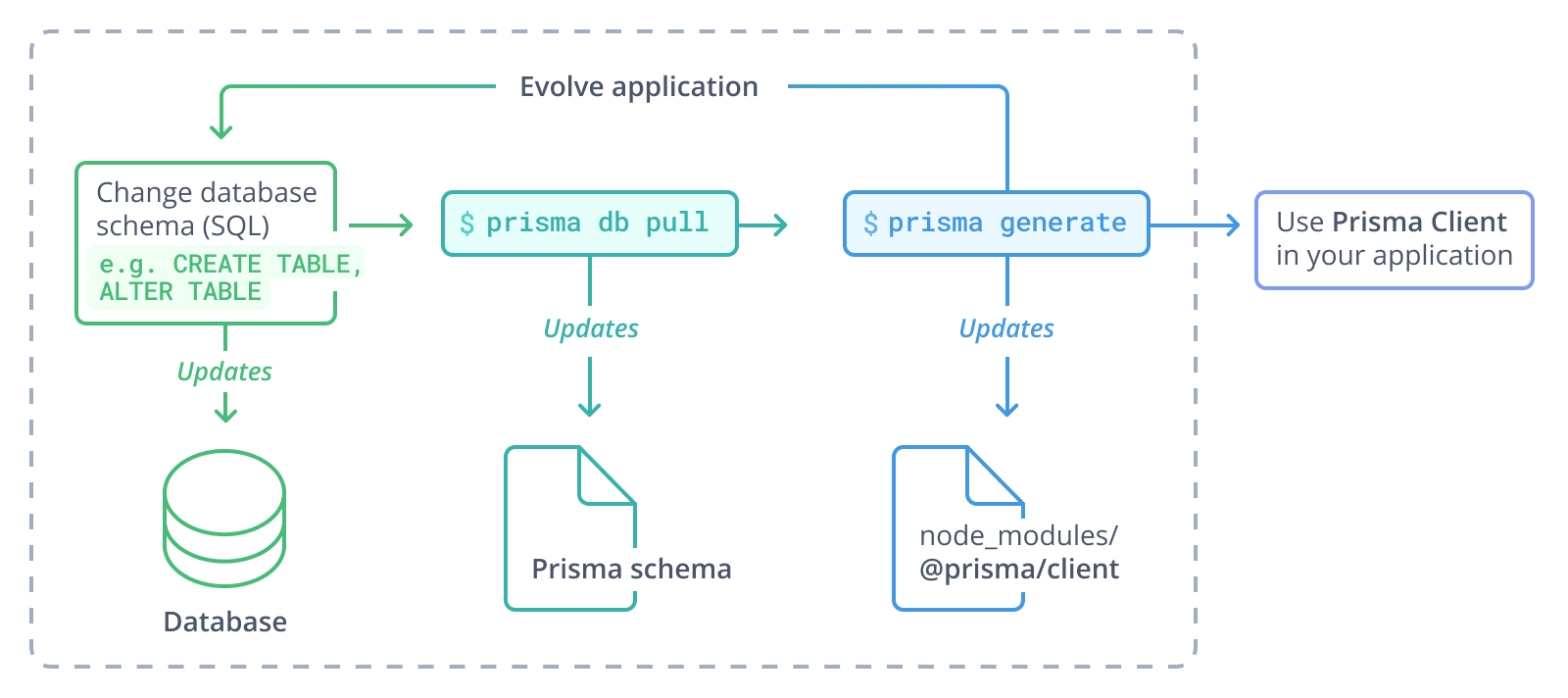
内省工作流
对于不使用 Prisma Migrate,而是使用纯 SQL 或其他迁移工具的项目,典型工作流如下
- 更改数据库 schema(例如使用纯 SQL)
- 运行
prisma db pull以更新 Prisma schema - 运行
prisma generate以更新 Prisma Client - 在您的应用程序中使用更新后的 Prisma Client
请注意,随着应用程序的发展,此过程可以无限次重复。
规则和约定
Prisma ORM 采用多种约定来将数据库 schema 转换为 Prisma schema 中的数据模型
模型、字段和枚举名称
字段、模型和枚举名称(标识符)必须以字母开头,并且通常只能包含下划线、字母和数字。您可以在相应的文档页面上找到这些标识符的命名规则和约定
标识符的一般规则是它们需要遵守此正则表达式
[A-Za-z][A-Za-z0-9_]*
无效字符的净化
无效字符在内省过程中会被净化
- 如果它们出现在标识符中字母之前,则会被丢弃。
- 如果它们出现在第一个字母之后,则会被替换为下划线。
此外,转换后的名称会使用 @map 或 @@map 映射到数据库,以保留原始名称。
以下表为例
CREATE TABLE "42User" (
_id SERIAL PRIMARY KEY,
_name VARCHAR(255),
two$two INTEGER
);
由于表名中开头的 42 以及列中开头的下划线和 $ 在 Prisma ORM 中是禁止的,因此内省会添加 @map 和 @@map 属性,以使这些名称符合 Prisma ORM 的命名约定
model User {
id Int @id @default(autoincrement()) @map("_id")
name String? @map("_name")
two_two Int? @map("two$two")
@@map("42User")
}
净化后的重复标识符
如果净化导致标识符重复,则不会立即进行错误处理。您稍后会收到错误并可以手动修复它。
考虑以下两个表的情况
CREATE TABLE "42User" (
_id SERIAL PRIMARY KEY
);
CREATE TABLE "24User" (
_id SERIAL PRIMARY KEY
);
这将导致以下内省结果
model User {
id Int @id @default(autoincrement()) @map("_id")
@@map("42User")
}
model User {
id Int @id @default(autoincrement()) @map("_id")
@@map("24User")
}
尝试使用 prisma generate 生成 Prisma Client 时,您将收到以下错误
npx prisma generate
$ npx prisma generate
Error: Schema parsing
error: The model "User" cannot be defined because a model with that name already exists.
--> schema.prisma:17
|
16 | }
17 | model User {
|
Validation Error Count: 1
在这种情况下,您必须手动更改两个生成的 User 模型中的一个的名称,因为 Prisma schema 中不允许重复的模型名称。
字段顺序
内省按照数据库中相应表列的顺序列出模型字段。
属性顺序
内省按照以下顺序添加属性(此顺序由 prisma format 镜像)
- 块级别:
@@id,@@unique,@@index,@@map - 字段级别:
@id,@unique,@default,@updatedAt,@map,@relation
关系
Prisma ORM 将数据库表上定义的外键转换为关系。
一对一关系
当表上的外键具有 UNIQUE 约束时,Prisma ORM 会向您的数据模型添加一对一关系,例如
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Profile" (
id SERIAL PRIMARY KEY,
"user" integer NOT NULL UNIQUE,
FOREIGN KEY ("user") REFERENCES "User"(id)
);
Prisma ORM 将其转换为以下数据模型
model User {
id Int @id @default(autoincrement())
Profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user Int @unique
User User @relation(fields: [user], references: [id])
}
一对多关系
默认情况下,Prisma ORM 会为您在数据库 schema 中找到的外键添加一对多关系到您的数据模型
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
"author" integer NOT NULL,
FOREIGN KEY ("author") REFERENCES "User"(id)
);
这些表被转换为以下模型
model User {
id Int @id @default(autoincrement())
Post Post[]
}
model Post {
id Int @id @default(autoincrement())
author Int
User User @relation(fields: [author], references: [id])
}
多对多关系
Prisma ORM 支持两种在 Prisma schema 中定义多对多关系的方式
隐式多对多关系在符合 Prisma ORM 关系表约定的情况下会被识别。否则,关系表将以模型的形式呈现在 Prisma schema 中(从而使其成为显式多对多关系)。
此主题在关于关系的文档页面上有广泛介绍。
消除关系歧义
Prisma ORM 通常在不需要时省略 @relation 属性上的 name 参数。考虑上一节中的 User ↔ Post 示例。@relation 属性只有 references 参数,name 被省略,因为在这种情况下不需要它
model Post {
id Int @id @default(autoincrement())
author Int
User User @relation(fields: [author], references: [id])
}
如果在 Post 表上定义了两个外键,则需要它
CREATE TABLE "User" (
id SERIAL PRIMARY KEY
);
CREATE TABLE "Post" (
id SERIAL PRIMARY KEY,
"author" integer NOT NULL,
"favoritedBy" INTEGER,
FOREIGN KEY ("author") REFERENCES "User"(id),
FOREIGN KEY ("favoritedBy") REFERENCES "User"(id)
);
在这种情况下,Prisma ORM 需要使用专用的关系名称来消除关系的歧义
model Post {
id Int @id @default(autoincrement())
author Int
favoritedBy Int?
User_Post_authorToUser User @relation("Post_authorToUser", fields: [author], references: [id])
User_Post_favoritedByToUser User? @relation("Post_favoritedByToUser", fields: [favoritedBy], references: [id])
}
model User {
id Int @id @default(autoincrement())
Post_Post_authorToUser Post[] @relation("Post_authorToUser")
Post_Post_favoritedByToUser Post[] @relation("Post_favoritedByToUser")
}
请注意,您可以将 Prisma-ORM 级别的关系字段重命名为您喜欢的任何名称,以便它在生成的 Prisma Client API 中看起来更友好。
使用现有 schema 进行内省
对于具有现有 Prisma Schema 的关系数据库,运行 prisma db pull 会将对 schema 进行的手动更改与数据库中的更改合并。(此功能首次在 2.6.0 版本中添加。)对于 MongoDB,目前内省仅用于初始数据模型。重复运行会导致自定义更改的丢失,如下所述。
关系数据库的内省会保留以下手动更改
model块的顺序enum块的顺序- 注释
@map和@@map属性@updatedAt@default(cuid())(cuid()是 Prisma-ORM 级别的函数)@default(uuid())(uuid()是 Prisma-ORM 级别的函数)- 自定义
@relation名称
注意:只会识别数据库级别模型之间的关系。这意味着**必须设置外键**。
schema 的以下属性由数据库决定
model块内字段的顺序enum块内值的顺序
注意:所有
enum块都列在model块下方。
强制覆盖
要覆盖手动更改,并仅基于内省的数据库生成 schema 并忽略任何现有的 Prisma Schema,请将 --force 标志添加到 db pull 命令中
npx prisma db pull --force
用例包括
- 您想从头开始,使用从底层数据库生成的 schema
- 您有一个无效的 schema,并且必须使用
--force才能使内省成功
仅内省数据库 schema 的子集
Prisma ORM 尚不支持仅内省数据库 schema 的子集。
但是,您可以通过创建一个新的数据库用户来实现这一点,该用户只拥有您希望在 Prisma schema 中表示的表的访问权限,然后使用该用户执行内省。内省将只包含新用户有权访问的表。
如果您的目标是将某些模型从Prisma Client 生成中排除,您可以将 @@ignore 属性添加到 Prisma schema 中的模型定义。被忽略的模型将从生成的 Prisma Client 中排除。
内省对不支持功能的警告
Prisma Schema Language (PSL) 可以表达 Prisma ORM 支持的目标数据库的大部分功能。但是,Prisma Schema Language 仍然需要表达一些功能和特性。
对于这些功能,Prisma CLI 将检测到您数据库中该功能的使用情况并返回警告。Prisma CLI 还会在 Prisma schema 中使用这些功能的模型和字段中添加注释。警告还将包含一个变通方案建议。
prisma db pull 命令将提示以下不支持的功能
您可以在 GitHub 上找到我们计划支持的功能列表(标记为 topic:database-functionality)。
内省对不支持功能的警告的变通方法
如果您正在使用关系数据库以及上一节中列出的上述任一功能
- 创建草稿迁移
npx prisma migrate dev --create-only - 添加在警告中显示的功能的 SQL。
- 将草稿迁移应用到您的数据库
npx prisma migrate dev