当多个团队共享一个数据库时,问题就会出现。数据库迁移会冲突,查询会变得臃肿,或者所有权变得模糊不清。
这篇博文将详细介绍大型团队如何使用SQL、ORM或两者结合的方式,在保持速度和自主性的同时,构建弹性数据工作流。我们将探讨诸如扩展与收缩模式、模式CI、查询约定以及如何判断何时使用原始SQL等实际模式。
如果你正在扩展团队和数据库,这篇文章就是为你准备的。

数据工作流在大规模使用时为何会崩溃
随着团队的壮大,它们常常在共享数据库环境中发生冲突。结果呢?草率的迁移、意想不到的表更改,以及没有人真正确定谁拥有什么。
当所有权模糊时,即使是善意的更改也可能导致故障。这在快速发展的产品团队中尤其常见,这些团队没有明确定义数据库协议。
一些常见的故障发生在以下情况:
- 一个团队发布了一个迁移,删除了另一个团队仍然需要的列
- 表因服务冲突目的的字段而变得臃肿
- 一个模式文件有五个所有者,但无人负责
有时,扩展的重点不是技术,而是清晰度。
选择一个工作流并使其无趣
让团队以多种方式管理同一任务可能看起来很灵活,但它通常会导致不一致和混乱。一个单一、无趣的工作流可以减少精神负担,促进更顺畅的协作。
团队管理模式更改的常见方法有三种:
提示:DDL代表数据定义语言——用于定义数据库结构的SQL语句,如
CREATE、ALTER或 DROP。
在所有团队中坚持一种方法。不加限制地混合风格会使你的工作流更难调试,几乎不可能扩展。
像对待应用程序代码一样对待模式
你会不经过拉取请求就发布应用程序代码吗?可能不会。数据库模式也值得同样级别的审查。
务必采取以下做法:
- 在Git中版本化每个模式更改
- 通过拉取请求审查模式更改
- 使用Prisma Migrate、Atlas或Liquibase等差异工具在更改上线前可视化更改
这会创建透明度,及早发现错误,并建立每次演变的S历史记录。
使用扩展与收缩模式
大的模式更改不必充满风险。“扩展与收缩”模式将更改分解为非破坏性步骤,以最大限度地减少停机时间。
- 扩展:添加新字段、表或结构
- 迁移:回填并更新所有引用或依赖项
- 收缩:只有在一切安全之后才删除或重命名旧部件
这避免了生产中断,支持滚动部署,并帮助团队保持正常运行时间,即使更改很复杂。

无论您使用原始SQL、Prisma、Rails或任何其他系统,这都是一个可靠的模式。访问我们的数据指南以了解有关扩展与收缩模式的更多信息。
定义何时使用SQL,何时使用ORM
SQL和ORM是互补而非竞争的工具。关键在于根据您的目标:开发速度、查询控制和长期可维护性,了解何时使用哪种工具更合适。
在以下情况下使用ORM:
- 您希望快速进行产品开发
- 您更喜欢可读、可维护且类型安全的代码
- 您的团队受益于抽象化样板代码和重复任务
- 您希望通过不要求每个开发人员都成为SQL专家来
降低开发风险
在以下情况下使用原始SQL:
- 您正在优化复杂的连接或性能关键路径
- 您需要对查询、索引或执行计划进行精细控制
- 您正在构建依赖自定义逻辑的、报表繁重的内部工具
您不必只选择一个。大多数现代应用程序都将两者结合:使用ORM快速开发并保持类型安全,并在性能或灵活性要求时回退到原始SQL——理想情况下将这些查询包装在类型化辅助函数中以保持可维护性。
例如,Prisma ORM中的TypedSQL允许您使用原始SQL并获得完整的TypeScript类型,就在您的ORM调用旁边。这为您提供了SQL的灵活性,同时不放弃类型安全或可维护性。
一些流行的工具包括:
Kysley (TypeScript), Sequelize (Node.js), Django ORM (Python), Knex (SQL builder), 通过 SQLX 或 pgx (Rust) 使用原始 SQL, 甚至使用带有迁移工具(如 Atlas 或 Liquibase)的 SQL 脚本。
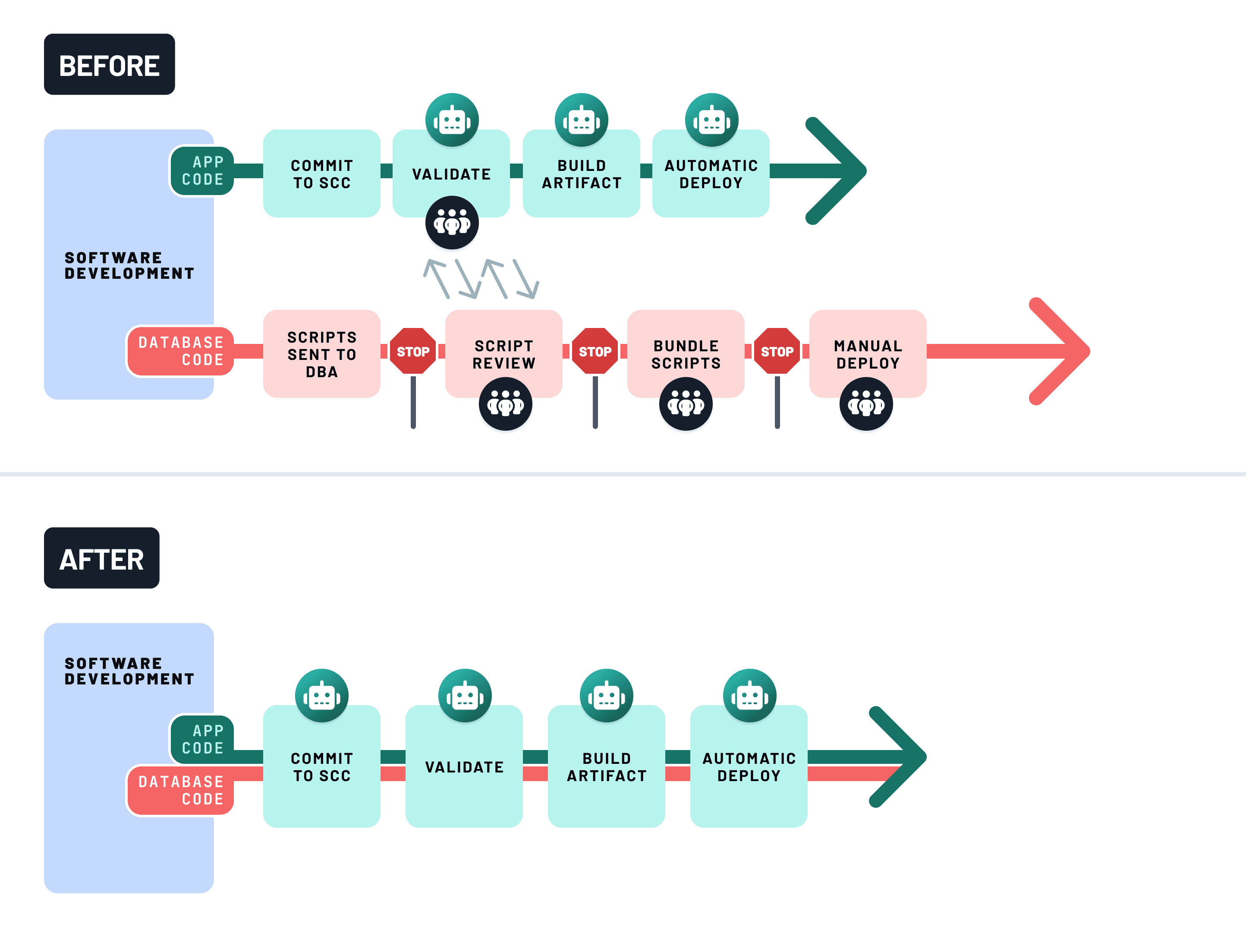
使用CI来强制执行数据库安全
没有保障措施,模式更改可能会悄无声息地破坏生产环境。持续集成 (CI) 通过在每次更改合并前进行验证来防止这种情况发生。
一个健壮的数据库CI管道应该:
- 预览模式差异,使用Prisma Migrate或Atlas等工具检测破坏性更改
- 运行集成测试,针对临时或影子数据库进行端到端行为验证
- 失败构建,如果检测到破坏性操作(例如,删除列、数据丢失)
使用 GitHub Actions、Docker 和您选择的迁移工具进行设置。例如,使用一个作业来:
- 启动一个干净的PostgreSQL容器
- 应用迁移
- 运行您的测试套件
- 解析迁移计划以查找潜在的不安全操作
这可以在回归问题影响生产之前将其捕获,并使模式演进成为您工作流中一个共享的、可审查的部分——而不是部署的副作用。
使用OpenAPI和Swagger定义边界
当团队通过API交换数据时,清晰的契约对于避免误解和错误至关重要。OpenAPI是一个广泛采用的规范,用于以结构化格式描述RESTful API,这种格式人类和工具都能理解。
Swagger是一套流行的工具,围绕OpenAPI标准构建。它允许团队以最小的摩擦文档、可视化和测试API。
使用Swagger等工具有助于团队:
- 明确定义API边界和预期行为
- 为前端和后端自动生成类型和客户端代码
- 验证更改以尽早发现破坏性更新
- 通过交互式文档浏览和测试API端点
- 通过模拟响应和集成类型化客户端来帮助前端团队更快地行动
- 通过使API自解释和可发现来改善开发人员的入职体验
这种方法在微服务架构或多个团队依赖共享内部API时特别有效。
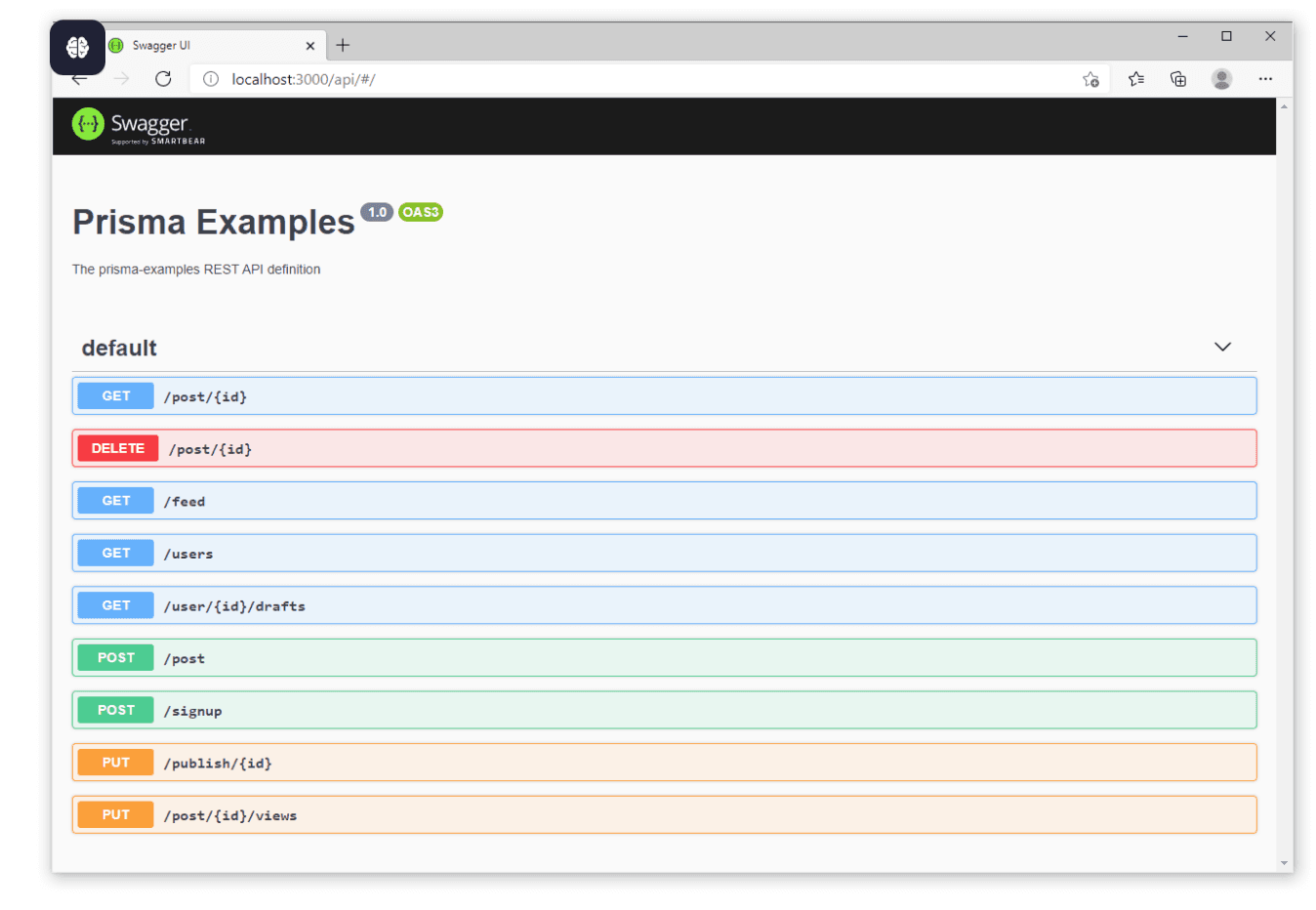
开发者无需依赖经验知识或Slack消息来解释 API 的工作原理,而是可以自信地探索、原型和集成——得益于准确、始终最新的文档。
协同定位查询,标准化结构
分散的逻辑难以扩展。一致的文件结构使您的代码库更易于导航、理解和扩展——尤其是在您的团队成长时。
不要将数据访问逻辑分散在 models/、utils/ 和 services/ 中,而是按领域分组查询。这反映了 CLEAN 架构 和 模块化单体 设计中的模式,其中特征边界——而非技术层——驱动结构。
为什么这有效:
- 鼓励每个领域的明确所有权和封装
- 通过使查询位置可预测来加速新成员的入职
- 减少横切关注点和不一致的抽象
- 使您的逻辑靠近其使用位置——更易于测试、文档和重构
像 CLEAN 或 基于功能的架构 这样的设计模式不仅仅是学术性的,它们还能随着时间的推移使协作更顺畅,系统更具弹性。一个好的结构会随着您的团队和产品一起扩展。
跨系统共享类型
前端和后端之间的类型不匹配是常见的bug来源——例如将 number 视为 string,或者缺少可选字段。这些问题通常发生在团队在多个地方定义相同的类型时,导致重复和偏差。
代码生成 通过直接从您的数据库模式或查询定义中生成类型来解决此问题。这为您提供了一个单一的事实来源,该来源在您的整个技术栈中保持同步。
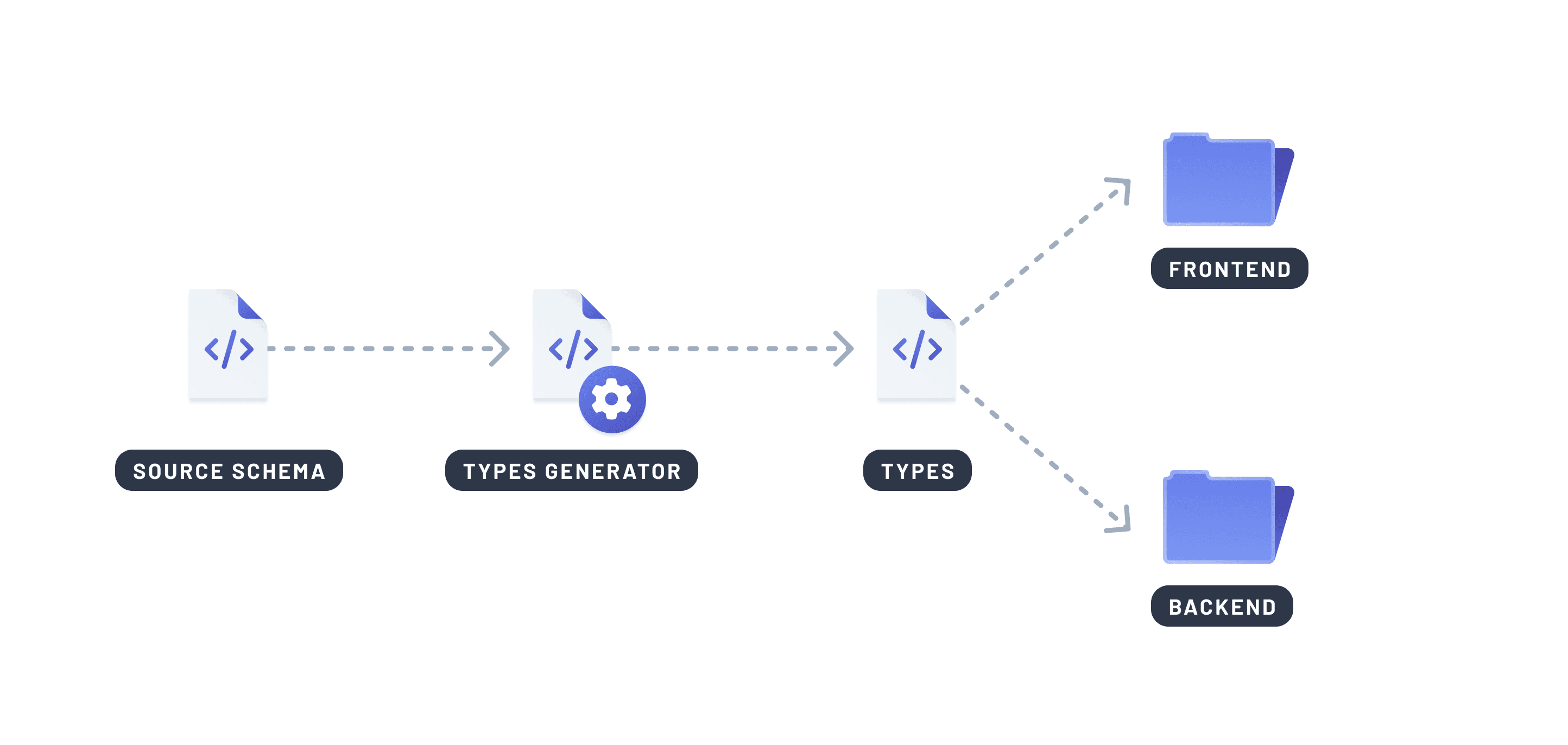
为什么这很重要:
- 避免了后端和前端之间类型的手动重复
- 防止由于类型不匹配或过时的契约导致的错误
- 在编译时而不是运行时强制执行正确性
- 通过更好的IDE支持和自动完成使重构更安全
有助于实现此目的的工具示例:Prisma ORM (TypeScript)、SQLC (Go)、SeaORM (Rust)、Pydantic (Python)
当你的应用程序层共享相同的类型定义时,你将减少bug,增加开发者的信心,并以更少的意外更快地发布。
让AI捕捉明显(和不那么明显)的问题
现代AI工具帮助团队在不牺牲质量的情况下更快地发展。通过将大型语言模型(LLMs)集成到您的开发工作流程中,您可以自动化繁琐的工作,捕捉细微的问题,并专注于解决实际问题。
使用LLM驱动的助手可以:
- 发现潜在不安全或破坏性的模式更改
- 总结拉取请求差异以加快审查速度
- 生成测试数据、边缘案例和种子场景
- 直接在拉取请求中推荐改进或标记风险
有助于实现此目的的工具示例:
Windsurf、CodiumAI、Sweep.dev (模式与PR审查)、GitHub Copilot、Cursor (内联编码辅助)、OpenDevin (后端自动化)。
这是来自Laravel生态系统的一个例子,名为Enlightn,一个扫描您的应用程序并在性能、安全性等方面提供可操作建议的工具。
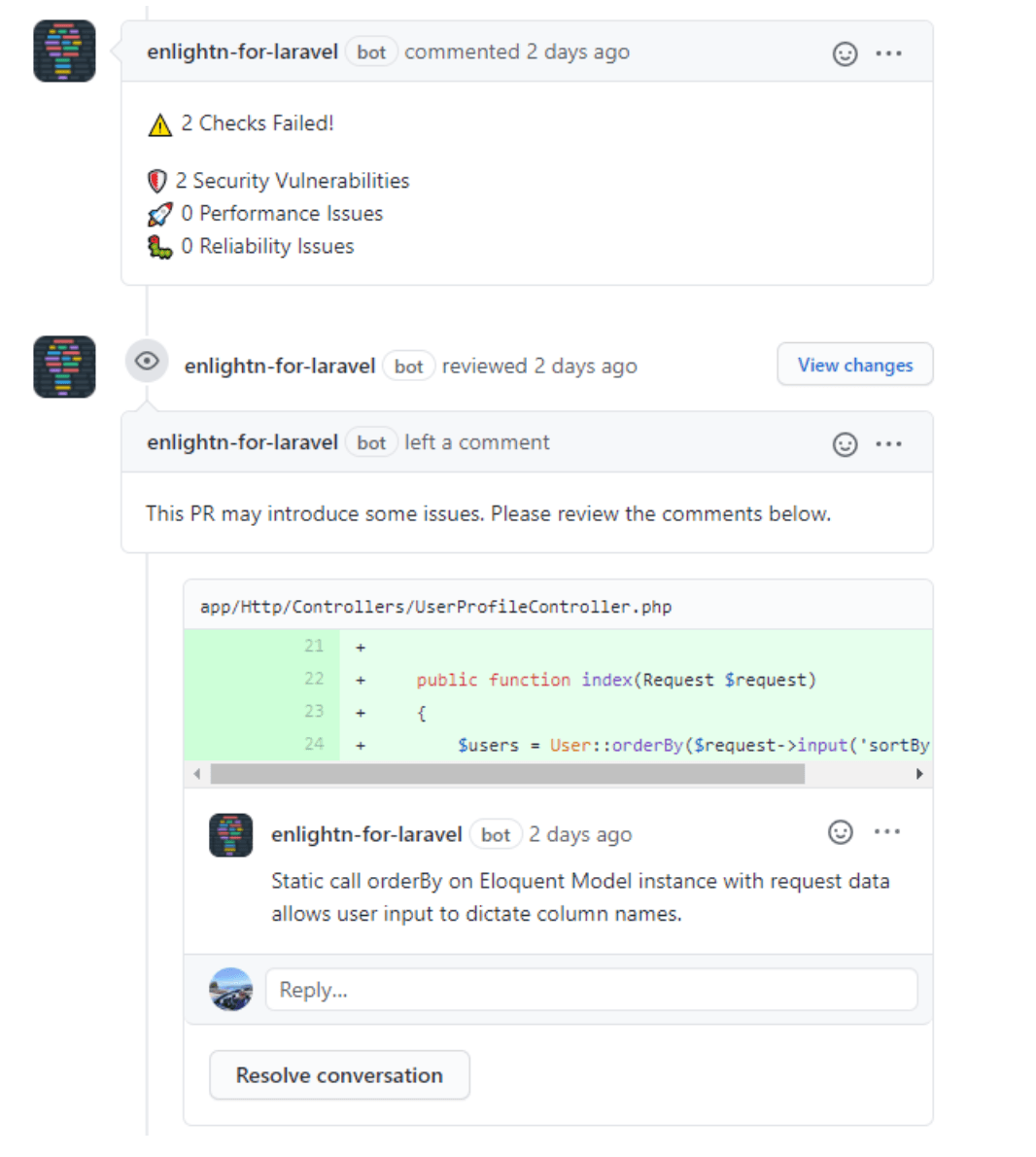
人工智能不仅仅是为了速度——它是你的第二双眼睛。明智地使用它,可以帮助你编写更安全的代码,减少审查疲劳,并卸载日常任务,让你能够专注于更宏大的目标。
优化团队速度,而非查询完美
精心调整的查询固然有价值,但可靠且一致的交付能力更重要。优先选择有助于整个团队更快地前进,同时不牺牲稳定性的工作流。
专注于以下流程:
- 鼓励安全的默认设置和合理的约定
- 使新开发人员的入职变得简单明了
- 通过工具和CI尽早发现问题
- 平衡性能与代码清晰度和可维护性
以速度为中心的实践示例:
使用带护栏的ORM、linter和格式化工具、类型安全的API,以及查询回归的CI检查。
快速的团队比拥有完美调优查询的团队交付更多价值,请优化与您的团队而非仅您的数据库一同扩展的工作流。
总结:构建工作流,而不是一团乱麻
你已经读到这里了——太棒了!这里有一个快速回顾,以帮助你牢记要点。请将此表视为诊断和改进当前设置的透镜,而不是一份清单。大多数大规模数据挑战与其说是技术问题,不如说是清晰度和一致性问题。
一个好的数据工作流是你的团队能够理解、信任并能改进的工作流。这才是可扩展的。选择纪律和清晰。当每个人都知道事情如何运作时,团队就能更快地协同工作。
加入对话,塑造更好的工作流
如果这对您有所帮助,我们很乐意听到。 在 X 上标记我们并分享您正在构建的内容。或者如果您想聊天、解决问题或深入探讨数据库和性能,请加入我们的 Discord。
我们还在YouTube上定期发布视频深度解析。如果您喜欢此类内容,请点击订阅。更多示例,更多性能技巧,也许还有一些惊喜发布。我们到时见。
不要错过下一篇文章!
订阅 Prisma 新闻通讯