现代无服务器和边缘运行时使得部署快速、可扩展的应用程序比以往任何时候都更容易。但是,随着应用程序变得越来越分布式,性能问题往往从代码转移到基础设施。
本文探讨了在全球分布式应用程序中常见的后端瓶颈:数据库往返时间长、连接抖动、冷启动和低效查询。本文还介绍了实用的解决方案,如连接池、缓存、区域感知部署和更智能的监控——从而无论您的用户身在何处,都能让您的应用程序保持高速运行。

边缘和无服务器的真正含义
在我们深入探讨之前,先快速定义一下这个领域。
无服务器意味着您编写一个函数,部署它,然后您的云提供商按需运行它。您不需要考虑基础设施。它会自动进行扩展。
边缘意味着这些函数在靠近您的用户的地方运行。您的代码可能为日本用户在东京运行,或为德国用户在法兰克福运行。这减少了物理距离,从而降低了延迟。
这对于前端响应能力和轻量级API非常有用——但它在幕后引入了新的挑战。
为什么无状态函数会使事情复杂化
其中一个挑战是无服务器和边缘函数是无状态的。它们在请求之间不保留状态。因此,每次有请求进来时,可能会启动一个新的实例,与您的数据库没有持久连接。
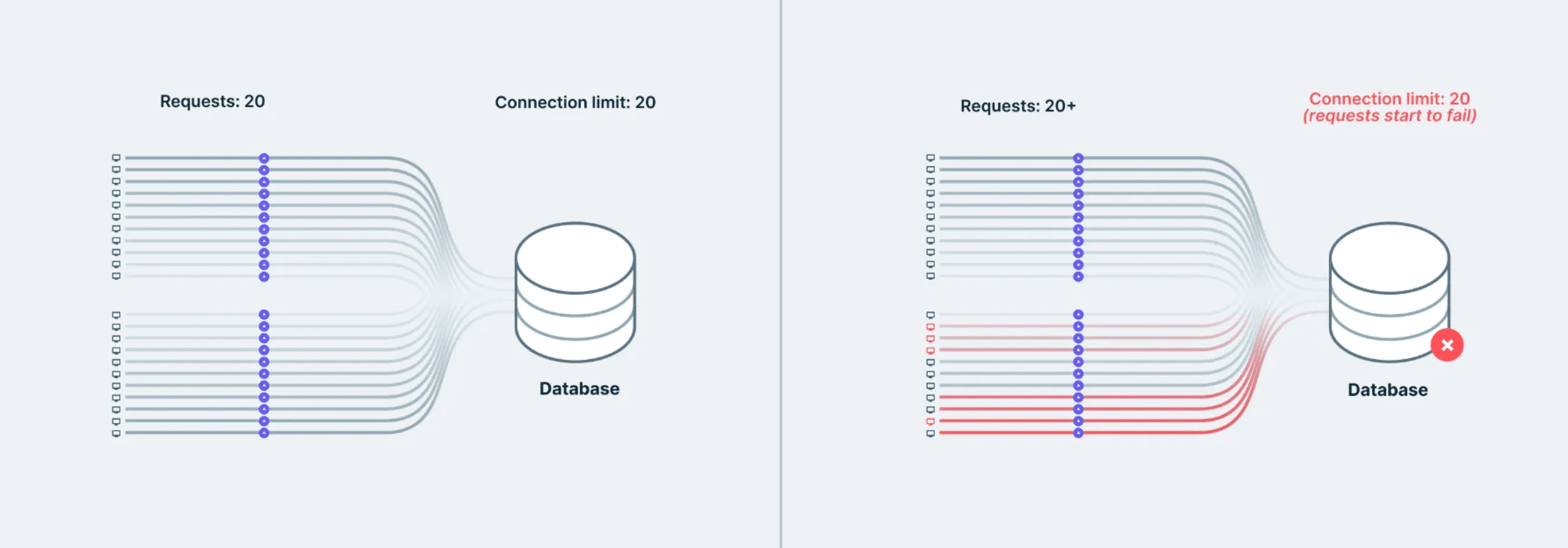
这导致了一个称为连接抖动的问题:数百个新连接被快速打开和关闭。
如果1000个用户同时访问您的函数,那意味着在短时间内会产生1000个数据库连接。大多数数据库都不是为此而构建的。您会达到连接限制,您的数据库开始限流,一切都会变慢。
冷启动加剧了这个问题。如果一个函数最近没有被使用,那么在运行时启动并建立新连接时,第一个请求会更慢。
使用连接池
解决方案是什么?连接池。
连接池允许多个函数调用共享一小组持久连接。它充当您数据库前面的队列。每个函数不是打开一个新连接,而是从池中获取一个连接。
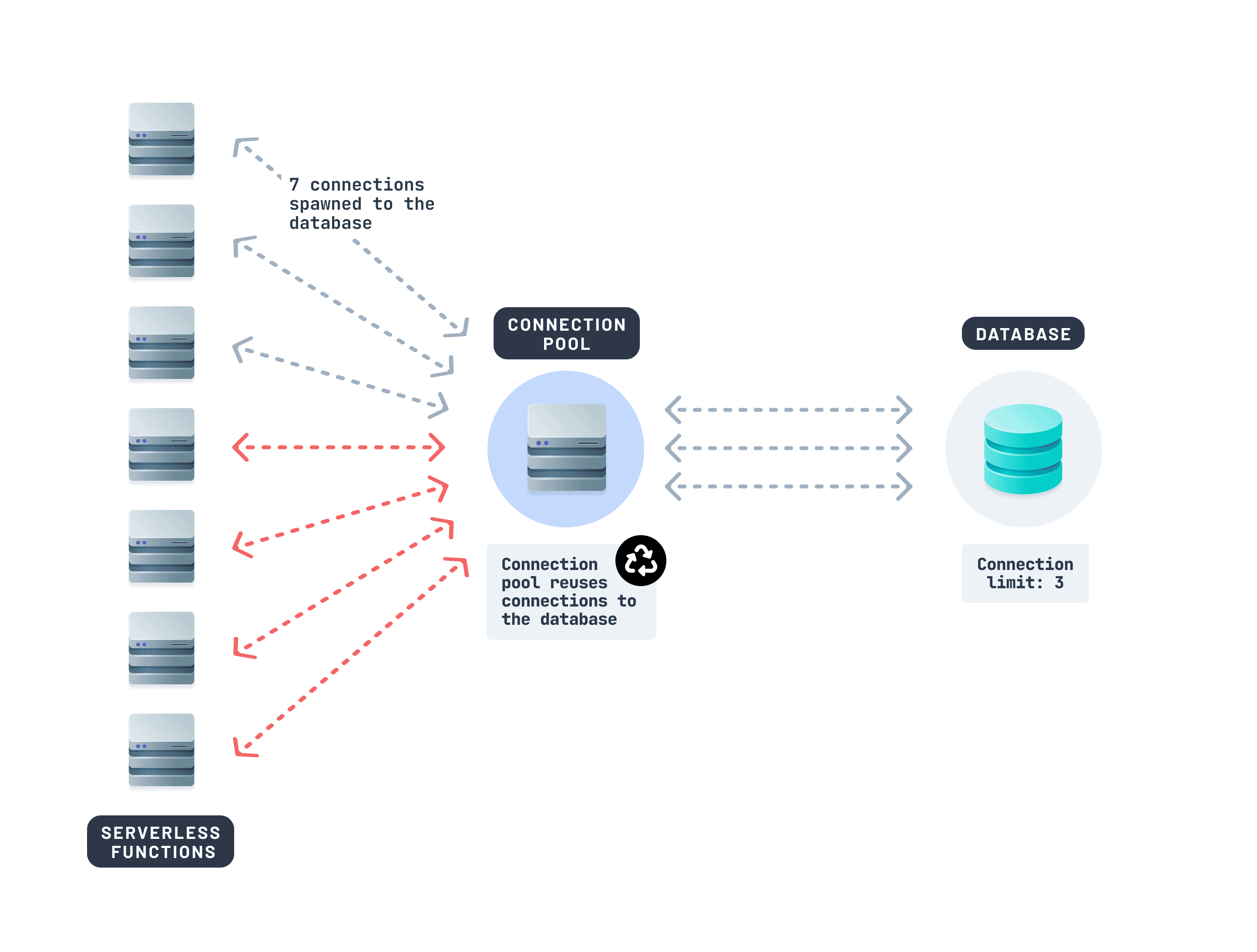
如果您正在使用像Prisma Postgres这样的数据库,连接池会在幕后自动处理——跨函数自动进行连接池和优化查询。其他工具,如PgBouncer或Supavisor(来自Supabase),也可能有用。
仅为您的数据库使用连接池器就可以在高流量边缘环境中稳定性能。
至此,我们已经解决了如何管理过多连接的问题。但导致边缘性能缓慢的另一个隐藏原因是。
您的边缘应用程序并不慢,是到数据库的往返时间慢
想象一下,您将边缘函数部署到东京。它运行速度飞快——直到它调用弗吉尼亚的数据库。突然,您的响应时间跳跃了500毫秒。
这不是您的代码的问题。这是地理位置的问题。
边缘运行时速度很快,但是如果您的函数必须跨越海洋查询数据库,每个请求都会增加数百毫秒的往返延迟。如果将其乘以多个查询,用户体验就会受到影响。
让我们探讨一下如何解决这个问题。
缓存不需要实时的数据
减少不必要数据库调用的最简单方法之一是缓存不经常更改的数据。
例如:产品列表、站点设置或功能标志。这些值不需要每次都重新获取。
您可以使用以下方式缓存数据库查询
- 通过适当的
Cache-Control头进行CDN级缓存 - 边缘键值数据库(如Vercel KV、Cloudflare Workers KV)
- 热无服务器函数中的内存缓存
- 使用具有内置缓存的数据库提供商,例如Prisma Postgres
缓存减轻了数据库的负载,并显著缩短了重复请求的往返时间。
将您的函数和数据库放置在同一位置
另一种加快API速度的方法是在同一区域运行您的代码和数据库。
假设您的数据库托管在us-east-1(弗吉尼亚)。但是您的边缘函数是从东京调用的。如果函数运行在靠近用户的地方(例如在ap-northeast-1),但数据库位于太平洋彼岸的美国,那么每个查询都必须进行长途网络往返——多次。
这就是延迟会快速增加的地方。
函数可能看起来像这样
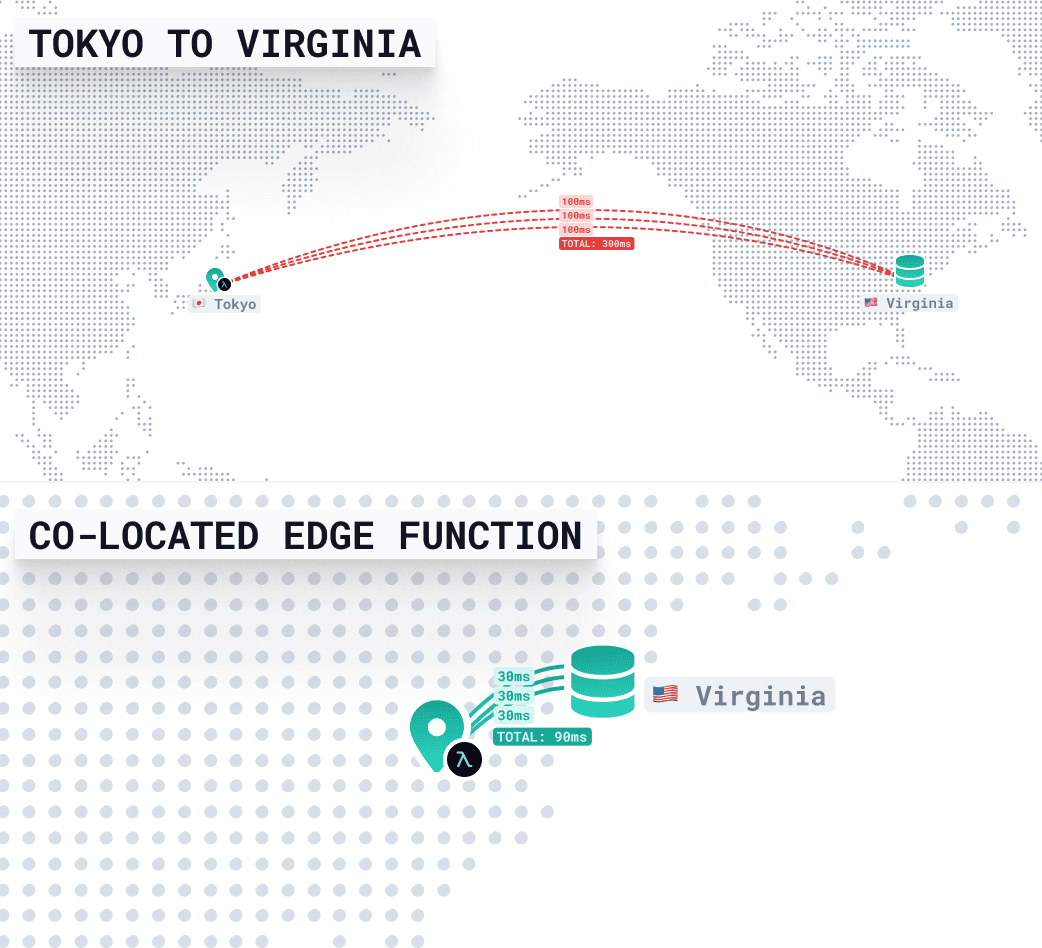
如果函数靠近用户(在东京),但远离数据库(在弗吉尼亚),则每个数据库查询都需要时间——由于跨太平洋网络延迟、TLS握手和DNS解析,每次往返大约300毫秒。
此处理程序按顺序运行三个依赖查询
- 3个查询 × 300毫秒 = 总延迟约900毫秒
因此,在您的函数进行任何实际工作之前,几乎一秒钟都花在等待数据上。
现在将它们放置在同一位置
通过将函数与您的数据库部署在同一区域(弗吉尼亚),这些查询不再需要跨越海洋。它们保持本地化——通常在10-30毫秒内完成。
这意味着即使请求来自东京,整个响应也可以在90毫秒以内返回。用户仍然需要等待一些与距离相关的延迟,但您的后端保持快速和一致。
区域绑定使其工作
Vercel、AWS Lambda等平台允许您将函数绑定到特定区域——在本例中为us-east-1。
对于Vercel中的边缘部署,region配置可以使您绑定区域
此设置在以下情况下是理想的
- 您按顺序运行多个查询
- 您希望避免编写复杂的客户端缓存
- 您关心稳定、低延迟的API
不是将后端分布在全球各地,而是将计算与数据放置在同一位置,只需一行配置即可避免数百毫秒的开销。
何时考虑多区域数据库
如果您的绝大多数用户都在读取数据,并且他们分布在全球各地,那么多区域数据库可以提供帮助。
这会将您的数据复制到不同区域,因此欧洲、亚洲或澳大利亚的用户可以从他们最近的副本读取数据。这可以改善延迟并减少单个数据库节点的负载。
AWS等云提供商提供多区域功能,如DynamoDB 全局表和Aurora 全局数据库,但像CockroachDB这样的专用数据库也使跨区域复制数据以获得更好性能变得容易。
分布式数据库在以下情况下是一个不错的选择
- 读取操作远多于写入操作
- 轻微的陈旧性(最终一致性)是可接受的
- 您想减少全球往返时间
但如果出现以下情况则暂停
- 您的应用程序需要严格的一致性(例如金融交易)
- 您在许多区域都有频繁的写入操作
- 您需要精确控制版本冲突
密切关注您的查询
即使您正在使用缓存并进行了同位放置,不良查询仍然会成为性能瓶颈。
尽早设置监控以跟踪百分位延迟
- p50 = 中位数查询时间
- p75 = 较慢的查询,通常在轻负载下
- p99 = 最坏情况的查询,通常是性能问题隐藏的地方
例如,p50为30毫秒很好——但如果您的p99为700毫秒,一些用户仍然会看到痛苦的延迟。
在识别性能瓶颈时,还要寻找
- N+1查询模式
- 过滤字段上缺少索引
- 过度获取嵌套数据
仅仅改进几个繁重的查询就可以将您的整体延迟减半。像Prisma Optimize这样的工具通过识别边缘和无服务器函数中最慢的查询、查明根本原因并建议可行的修复方法,使此过程变得更容易。

快速回顾
以下是问题及其解决方案的快速概览。
最终想法
部署到边缘很容易。但要让您的应用程序感觉快速——尤其是在全球范围内——则需要更多的思考。
好消息是?您不需要重建您的技术栈。一些小的改变——缓存、同位放置、连接池和监控——可以带来巨大的不同。
下次您的边缘函数开始变慢时,很少是计算问题。十有八九是您的数据库。通常那是减速开始的地方,也是速度提升所在。
让我们继续交流
如果这对您有所帮助,我们很乐意听到。在X上标记我们并分享您正在构建的内容。或者如果您想聊天、故障排除或讨论数据库和性能,可以加入我们的Discord。
我们还会定期在YouTube上发布深入的视频。如果您喜欢这类内容,请点击订阅。更多示例、更多性能技巧,也许还有一些惊喜发布。我们将在那里见到您。
不要错过下一篇文章!
订阅 Prisma 新闻通讯