GraphQL 服务器的结构和实现(第一部分)
刚开始接触 GraphQL 时,首先要问的问题之一是:我如何构建一个 GraphQL 服务器?由于 GraphQL 只是作为规范发布的,所以你的 GraphQL 服务器实际上可以用你喜欢的任何编程语言实现。
在开始构建服务器之前,GraphQL 要求你设计一个schema,它反过来定义了服务器的 API。在这篇文章中,我们将了解 schema 的主要组件,阐明实际实现它的机制,并学习 GraphQL.js、graphql-tools 和 graphene-js 等库如何帮助你完成这个过程。
本文仅涉及纯 GraphQL 功能 — 没有网络层的概念来定义服务器如何与客户端通信。重点是“GraphQL 执行引擎”的内部工作原理和查询解析过程。要了解网络层,请查看下一篇文章。
GraphQL schema 定义服务器的 API
定义 Schema:Schema 定义语言
GraphQL 有自己的类型语言,用于编写 GraphQL schema:Schema 定义语言(SDL)。最简单的形式是,GraphQL SDL 可以用于定义如下所示的类型:
单独的 User 类型不向客户端应用程序暴露任何功能,它只是定义了应用程序中用户模型的结构。为了向 API 添加功能,你需要将字段添加到 GraphQL schema 的根类型:Query、Mutation 和 Subscription。这些类型定义了 GraphQL API 的入口点。
例如,考虑以下查询:
仅当相应的 GraphQL schema 定义了具有以下 user 字段的 Query 根类型时,此查询才有效:
因此,schema 的根类型决定了服务器将接受的查询和变更的形状。
GraphQL schema 为客户端-服务器通信提供了清晰的契约。
GraphQLSchema 对象是 GraphQL 服务器的核心
GraphQL.js 是 Facebook 的 GraphQL 参考实现,为其他库(如 graphql-tools 和 graphene-js)提供了基础。当使用这些库中的任何一个时,你的开发过程都围绕着一个 GraphQLSchema 对象,它由两个主要组件组成:
- schema 定义
- 以解析器函数形式的实际实现
对于上面的示例,GraphQLSchema 对象如下所示:
如你所见,schema 的 SDL 版本可以直接转换为 GraphQLSchema 类型的 JavaScript 表示。请注意,此 schema 没有解析器 — 因此它不允许你实际执行任何查询或变更。下一节将详细介绍。
解析器实现 API
GraphQL 服务器中的结构与行为
GraphQL 明确区分了结构和行为。GraphQL 服务器的结构——正如我们刚刚讨论的——是它的 schema,对服务器功能的抽象描述。这种结构通过一个具体的实现变得生动起来,该实现决定了服务器的行为。实现的关键组件是所谓的解析器函数。
GraphQL schema 中的每个字段都由一个解析器支持。
在其最基本的形式中,GraphQL 服务器的 schema 中每个字段都有一个解析器函数。每个解析器都知道如何为其字段获取数据。由于 GraphQL 查询本质上只是字段的集合,因此 GraphQL 服务器要收集请求的数据,实际上只需调用查询中指定字段的所有解析器函数即可。(这也是为什么 GraphQL 经常与RPC 风格的系统进行比较,因为它本质上是一种调用远程函数的语言。)
解析器函数剖析
使用 GraphQL.js 时,GraphQLSchema 对象中类型的每个字段都可以附加一个 resolve 函数。让我们考虑上面的示例,特别是 Query 类型上的 user 字段——这里我们可以添加一个简单的 resolve 函数,如下所示:
假设函数 fetchUserById 确实可用并返回一个 User 实例(一个带有 id 和 name 字段的 JS 对象),那么 resolve 函数现在就可以执行 schema 了。
在我们深入探讨之前,先花点时间理解传入解析器的四个参数:
root(有时也称为parent):还记得我们说过 GraphQL 服务器要解析查询,只需调用查询字段的解析器吗?嗯,它是广度优先(逐级)地这样做的,每个解析器调用中的root参数只是前一个调用的结果(如果未另行指定,初始值为null)。args:此参数携带查询的参数,在本例中是待获取User的id。context:一个通过解析器链传递的对象,每个解析器都可以写入和读取(基本上是解析器通信和共享信息的方式)。info:查询或变更的 AST 表示。你可以在本系列的第三部分了解更多详细信息:揭秘 GraphQL 解析器中的 info 参数。
之前我们说过,GraphQL schema 中的每个字段都由一个解析器函数支持。目前我们只有一个解析器,而我们的 schema 总共有三个字段:Query 类型上的根字段 user,以及 User 类型上的 id 和 name 字段。剩下的两个字段仍然需要它们的解析器。如你所见,这些解析器的实现非常简单:
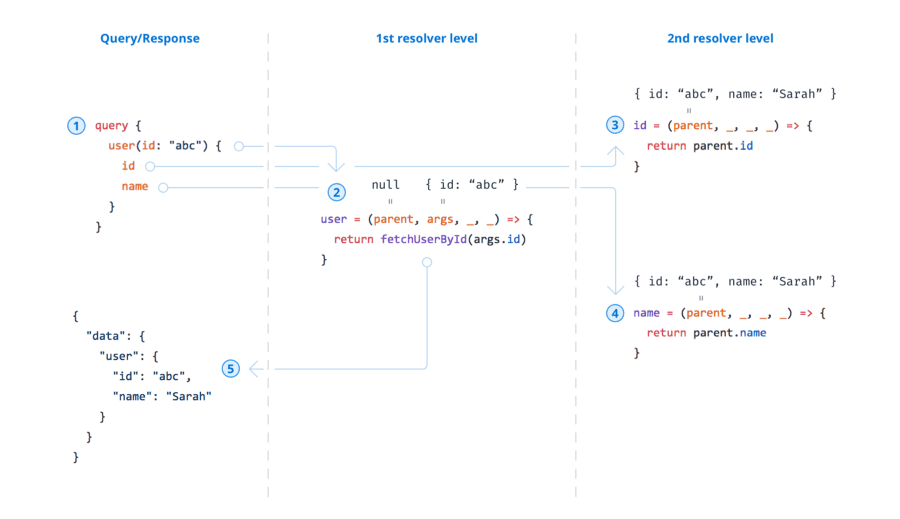
查询执行
考虑到我们上面的查询,让我们了解它是如何执行和收集数据的。查询总共包含三个字段:user(根字段)、id 和 name。这意味着当查询到达服务器时,服务器需要调用三个解析器函数——每个字段一个。让我们来看看执行流程:

- 查询到达服务器。
- 服务器调用根字段
user的解析器——假设fetchUserById返回这个对象:{ "id": "abc", "name": "Sarah" } - 服务器调用
User类型上id字段的解析器。此解析器的root输入参数是前一次调用的返回值,因此它可以简单地返回root.id。 - 与 3 类似,但最终返回
root.name。(注意 3 和 4 可以并行发生。) - 解析过程终止——最后结果被
data字段包装,以符合 GraphQL 规范:
现在,你真的需要自己为 user.id 和 user.name 编写解析器吗?使用 GraphQL.js 时,如果实现像示例中那样简单,则无需实现解析器。因此,你可以省略它们的实现,因为 GraphQL.js 已经根据字段名称和根参数推断出它需要返回什么。
优化请求:DataLoader 模式
使用上述执行方法,当客户端发送深度嵌套的查询时,很容易遇到性能问题。假设我们的 API 还有包含评论的文章,并且允许这样的查询:
注意,我们正在请求给定 user 的特定 article,以及它的 comments 和撰写这些评论的用户的 name。
假设这篇文章有五条评论,都由同一个用户撰写。这意味着我们将五次命中 writtenBy 解析器,但它每次都只会返回相同的数据。DataLoader 允许你在这种情况下进行优化,以避免 N+1 查询问题——一般的想法是解析器调用被批处理,因此数据库(或其他数据源)只需命中一次。
要了解有关 DataLoader 的更多信息,你可以观看 Lee Byron 的这部精彩视频:DataLoader — 源代码演练(约 35 分钟)
GraphQL.js 与 graphql-tools
现在我们来谈谈可用的库,它们可以帮助你在 JavaScript 中实现 GraphQL 服务器——主要是 GraphQL.js 和 graphql-tools 之间的区别。
GraphQL.js 为 graphql-tools 提供了基础
要理解的第一个关键点是 GraphQL.js 为 graphql-tools 提供了基础。它通过定义所需的类型、实现 schema 构建以及查询验证和解析,完成了所有繁重的工作。graphql-tools 然后在 GraphQL.js 之上提供了一个薄薄的便利层。
让我们快速浏览一下 GraphQL.js 提供的一些功能。请注意,其功能通常围绕 GraphQLSchema 展开:
parse和buildASTSchema:给定以 GraphQL SDL 字符串形式定义的 GraphQL schema,这两个函数将创建一个 GraphQLSchema 实例:const schema = buildASTSchema(parse(sdlString))。validate:给定一个GraphQLSchema实例和一个查询,validate确保查询符合 schema 定义的 API。execute:给定一个GraphQLSchema实例和一个查询,execute调用查询字段的解析器,并根据 GraphQL 规范创建响应。当然,这只有在解析器是GraphQLSchema实例的一部分时才有效(否则它只是一份有菜单但没有厨房的餐厅)。printSchema:接受一个GraphQLSchema实例并以 SDL(作为字符串)返回其定义。
请注意,GraphQL.js 中最重要的函数是 graphql,它接受一个 GraphQLSchema 实例和一个查询,然后调用 validate 和 execute:
要了解所有这些功能,请查看这个简单的 Node 脚本,它在一个简单的示例中使用了它们。
graphql 函数针对一个 schema 执行 GraphQL 查询,该 schema 本身已经包含结构和行为。graphql 的主要作用是协调解析器函数的调用,并根据所提供查询的形状打包响应数据。在这方面,graphql 函数实现的功能也被称为 GraphQL 引擎。
graphql-tools:连接接口与实现
使用 GraphQL 的一个好处是,你可以采用Schema-first开发流程,这意味着你构建的每个功能首先都在 GraphQL Schema 中体现出来——然后通过相应的解析器实现。这种方法有很多好处,例如它允许前端开发人员在后端开发人员实际实现 API 之前,就可以使用模拟 API 进行工作——这归功于 SDL。
GraphQL.js 最大的缺点是它不允许你用 SDL 编写 schema,然后轻松生成
GraphQLSchema的可执行版本。
如上所述,你可以使用 parse 和 buildASTSchema 从 SDL 创建 GraphQLSchema 实例,但这缺少使执行成为可能所需的 resolve 函数!使你的 GraphQLSchema 可执行(使用 GraphQL.js)的唯一方法是手动将 resolve 函数添加到 schema 的字段中。
graphql-tools 用一个重要的功能弥补了这一空白:addResolveFunctionsToSchema。这非常有用,因为它提供了一个更好的、基于 SDL 的 API 来创建你的 schema。这正是 graphql-tools 用 makeExecutableSchema 所做的事情:
所以,使用 graphql-tools 的最大好处是它提供了一个很好的 API 来连接你的声明性 schema 和解析器!
何时不使用 graphql-tools?
我们刚刚了解到 graphql-tools 的核心是提供了一个 GraphQL.js 之上的便利层,那么有没有不适合用它来实现服务器的情况呢?
与大多数抽象一样,graphql-tools 通过牺牲其他地方的灵活性来简化某些工作流。它提供了出色的“入门”体验,并在快速构建 GraphQLSchema 时避免了摩擦。但是,如果你的后端有更自定义的需求,例如动态构建和修改 schema,它的限制可能有点太紧——在这种情况下,你可以回退到使用 GraphQL.js。
关于 graphene-js 的简要说明
graphene-js 是一个新的 GraphQL 库,它遵循其Python 对应库的思想。它也在底层使用 GraphQL.js,但不允许在 SDL 中声明 schema。
graphene-js 深入拥抱了现代 JavaScript 语法,提供了一个直观的 API,其中查询和变更可以作为 JavaScript 类实现。看到更多的 GraphQL 实现涌现出来,以新的思想丰富生态系统,这真是令人兴奋!
结论
在本文中,我们揭示了 GraphQL 执行引擎的机制和内部工作原理。从定义服务器 API 并确定将接受哪些查询和变更以及响应格式的 GraphQL schema 开始。然后我们深入研究了解析器函数,并概述了 GraphQL 引擎在解析传入查询时启用的执行模型。最后总结了可用的 JavaScript 库,这些库可以帮助你实现 GraphQL 服务器。
如果您想获得本文中讨论内容的实用概述,请查看此存储库。请注意,它有一个
graphql-js和graphql-tools分支,用于比较不同的方法。
一般来说,重要的是要注意 GraphQL.js 提供了构建 GraphQL 服务器所需的所有功能——graphql-tools 只是在其之上实现了一个便利层,满足了大多数用例并提供了出色的“入门”体验。只有在对构建 GraphQL schema 有更高级的要求时,才可能需要放下手套并使用纯 GraphQL.js。
在下一篇文章中,我们将讨论网络层和用于实现 GraphQL 服务器的不同库,例如 express-graphql、apollo-server 和 graphql-yoga。第 3 部分将介绍 GraphQL 解析器中 info 对象的结构和作用。
不要错过下一篇文章!
订阅 Prisma 新闻通讯