从多个表中连接数据是一个复杂的话题。主要有两种策略:数据库级别连接和应用程序级别连接。Prisma ORM 提供这两种选项。在本文中,您将了解这两种策略之间的权衡,以便为您的用例选择最佳策略。

简介
为什么 Prisma ORM 最初只支持应用程序级连接?
Prisma ORM 最初只提供应用程序级连接策略。这有几个原因
- 能够在不同的数据库引擎中使用相同的连接策略,确保可移植性。
- 通过将昂贵的操作转移到应用程序层(应用程序层比数据库更容易且成本更低),提高了整个系统的可扩展性。
- 在云原生和无服务器用例中,应用程序和数据库在同一云区域共置是常态,额外的数据库往返开销可以忽略不计。
- 具有数百万行和深度嵌套查询的高性能用例,使用额外的功能如过滤和分页。
- 查询调试简单,因为每个查询只针对一个表(无需理解和调试复杂的查询计划)。
- 通过将数据库的职责限制为直接操作,并防止查询性能因数据库的查询规划器和运行时优化而出现显著变化,从而实现可预测的性能。
2024年2月,Prisma ORM 增加了智能数据库级连接作为替代策略,使用 LATERAL 连接和 JSON 聚合等现代数据库功能。当应用程序和数据库服务器彼此相距较远,且额外网络往返的成本对查询的总体延迟有显著影响时,这种方法是有利的。
最终,这些方法各有优缺点,我们将在本文的其余部分阐明这些,以帮助您为关系查询选择最佳策略。
嵌套对象与外键关系
在深入探讨连接的复杂性之前,让我们快速回顾一下,了解“连接数据”这一主题的全部内容。
作为一名开发人员,您可能习惯于使用嵌套对象,它们看起来与此类似
在此示例中,“对象层级”如下:post → author → profile。
这种嵌套结构是大多数具有对象概念的编程语言中数据表示的方式。
然而,如果您之前使用过 SQL 数据库,您可能会意识到相关数据在那里的表示方式不同,即以 扁平 (或 规范化)的方式表示。通过这种方法,实体之间的关系通过 外键 表示,这些外键指定了表之间的引用。
这是这两种方法的视觉表示
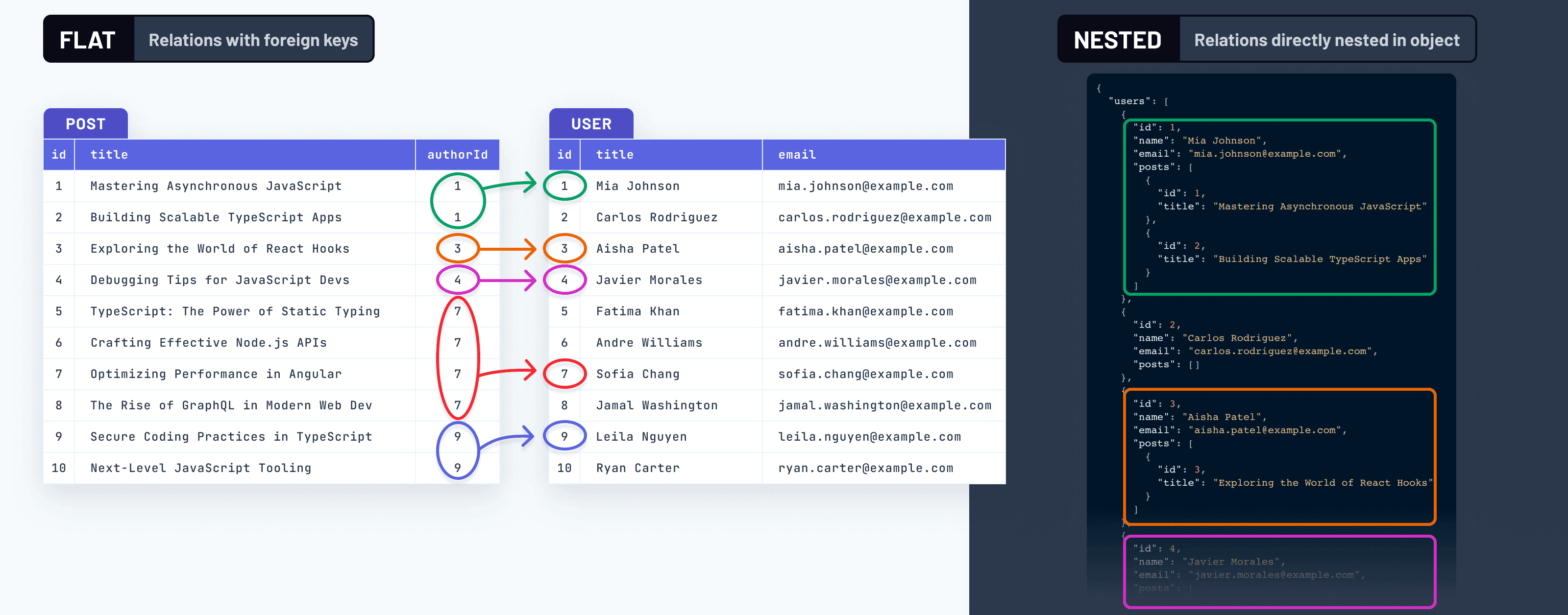
这是一个巨大的差异,不仅在于数据在 物理 磁盘和内存中的布局方式,还在于 心智模型 和数据推理方式。
“连接”数据意味着什么?
连接数据的过程是指将 SQL 数据库中的扁平布局数据转换为应用程序开发人员可在其应用程序中使用的嵌套结构。
这可以在以下两个地方之一发生
- 在 数据库中:单个 SQL 查询发送到数据库。该查询使用
JOIN关键字(或可能是关联子查询),让数据库执行跨多个表的连接并返回嵌套结构。有多种执行此连接的方法,我们将在下一节中探讨。 - 在 应用程序中:多个查询发送到数据库。每个查询只访问一个表,然后查询结果在应用程序层进行连接。
数据库级连接有其优点,但如果变得过于复杂,也会有一些缺点。因此,根据模式、数据集和查询复杂性等因素,任一方法都可能比另一种方法更适合特定用例。请继续阅读以了解详细信息!
三种 JOIN 策略:朴素、智能和应用程序级 JOIN
从宏观上看,可以应用三种不同的连接策略:数据库级别的“朴素”和“智能” JOIN,以及“应用程序级” JOIN。让我们通过以下模式逐一考察它们
朴素的数据库级 JOIN 导致数据冗余
朴素的数据库级 JOIN 指的是未采取任何额外优化措施的 JOIN 操作。这类 JOIN 通常会因多种原因而导致性能不佳,让我们来探讨一下!
例如,这是一个简单的 LEFT JOIN 操作,开发人员可能会朴素地编写它来连接 users 表和 post 表中的数据
数据库返回的结果可能类似于此

您注意到什么了吗?user_name 列的数据中存在大量重复。
现在,让我们将 comments 添加到查询中
现在更糟糕了!不仅 user_name 重复,post_title 也重复了
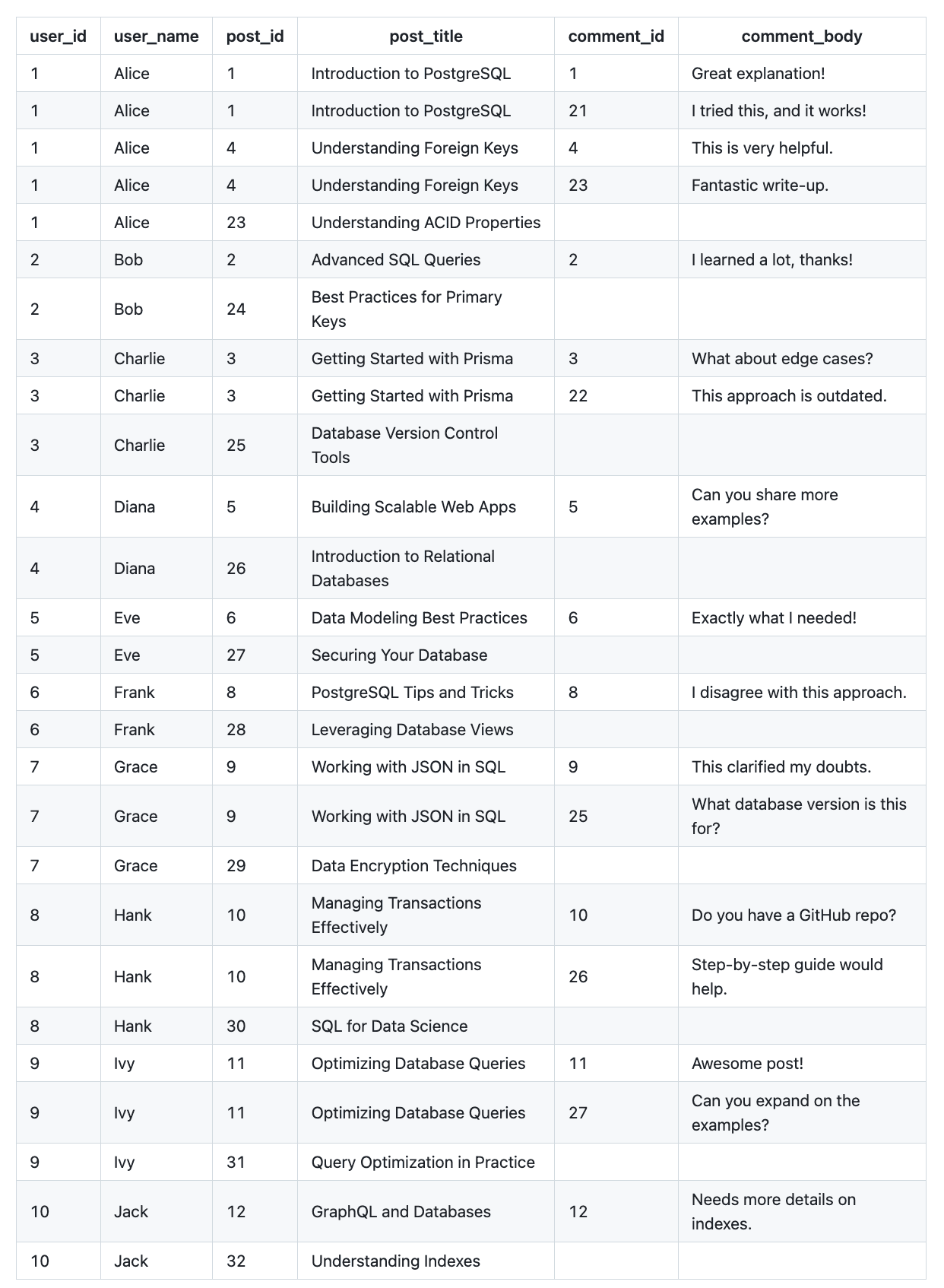
数据的冗余带来了几个负面影响
- 通过网络发送的数据量(不必要的)增加,消耗网络带宽并增加整体查询延迟。
- 应用程序层需要做额外的工作才能获得所需的嵌套对象
- 对冗余数据进行去重
- 重建数据记录之间的关系
此外,这种操作会给数据库带来高 CPU 开销,因为它将查询所有三个表并执行自己的内存映射,将数据连接成一个结果集。
以上仍然是一个相对简单的例子。想象一下,如果您使用更多的 JOIN 和更深层次的嵌套执行此操作。达到一定级别后,数据库将放弃优化查询计划,转而为每个表执行全表扫描,然后使用自己的 CPU 在内存中拼接数据。这会很快变得昂贵!
数据库 CPU 和内存的扩展比应用程序级 CPU 和内存复杂得多(且成本更高)。因此,改善这种情况的一种方法是利用应用服务器的 CPU 来完成数据连接的工作,这引出了下一种方法:“应用程序级连接”。
应用程序级连接简单高效,但有网络成本
另一种执行这些朴素的数据库级连接的替代方法是在应用程序层连接数据。在这种情况下,开发人员会编写三个不同的查询,分别发送到数据库。一旦数据库返回查询结果,开发人员就可以应用自己的业务逻辑来连接数据。
在 TypeScript 中,一个示例如下(使用普通的 Postgres 驱动程序,如 node-postgres)
这种方法有几个优点
- 数据库将为每个查询生成高度优化的执行计划,并且几乎不执行 CPU 工作,因为它只是从单个表中返回数据。
- 通过网络发送的数据针对应用程序的数据需求进行了优化(并且不会像朴素的数据库级连接策略那样出现相同的冗余问题)。
- 由于大部分映射和连接工作现在都在应用程序本身完成,数据库服务器有更多资源来处理更复杂的查询。
通过将 CPU 成本从数据库转移到应用程序层,这种方法增强了整个系统的横向可扩展性。
在 O'Reilly 出版社的《高性能 MySQL》一书中,这种应用程序级连接技术被称为连接分解:“许多高性能网站使用 连接分解。您可以通过运行多个单表查询而不是多表连接来分解连接,然后在应用程序中执行连接。”
然而,一个主要缺点是它需要多次往返数据库。如果应用程序服务器和数据库彼此相距较远,这是一个重要的因素,会对性能产生严重影响,并可能使此策略不可行。但如果数据库和应用程序托管在同一区域,网络开销通常可以忽略不计,并且这种方法总体上可能更具性能优势。
智能数据库级连接解决冗余问题
朴素的数据库级连接几乎从来都不是从数据库中检索相关数据的最佳方式,但这是否意味着您的数据库永远不应该负责连接数据?当然不是!
过去几年,数据库引擎变得非常强大,并不断改进它们优化查询的方式。为了使数据库能够生成最优的查询计划,最重要的是它能理解查询的意图。
这有两个不同的因素
- 使用 JSON 聚合等技术减少冗余
- 使用现代数据库功能,如 PostgreSQL 中的
LATERAL连接(或 MySQL 中的关联子查询),这些功能包含查询复杂性
使用上述相同的模式示例,一个很好的表示方式是
这样的查询会产生以下结果
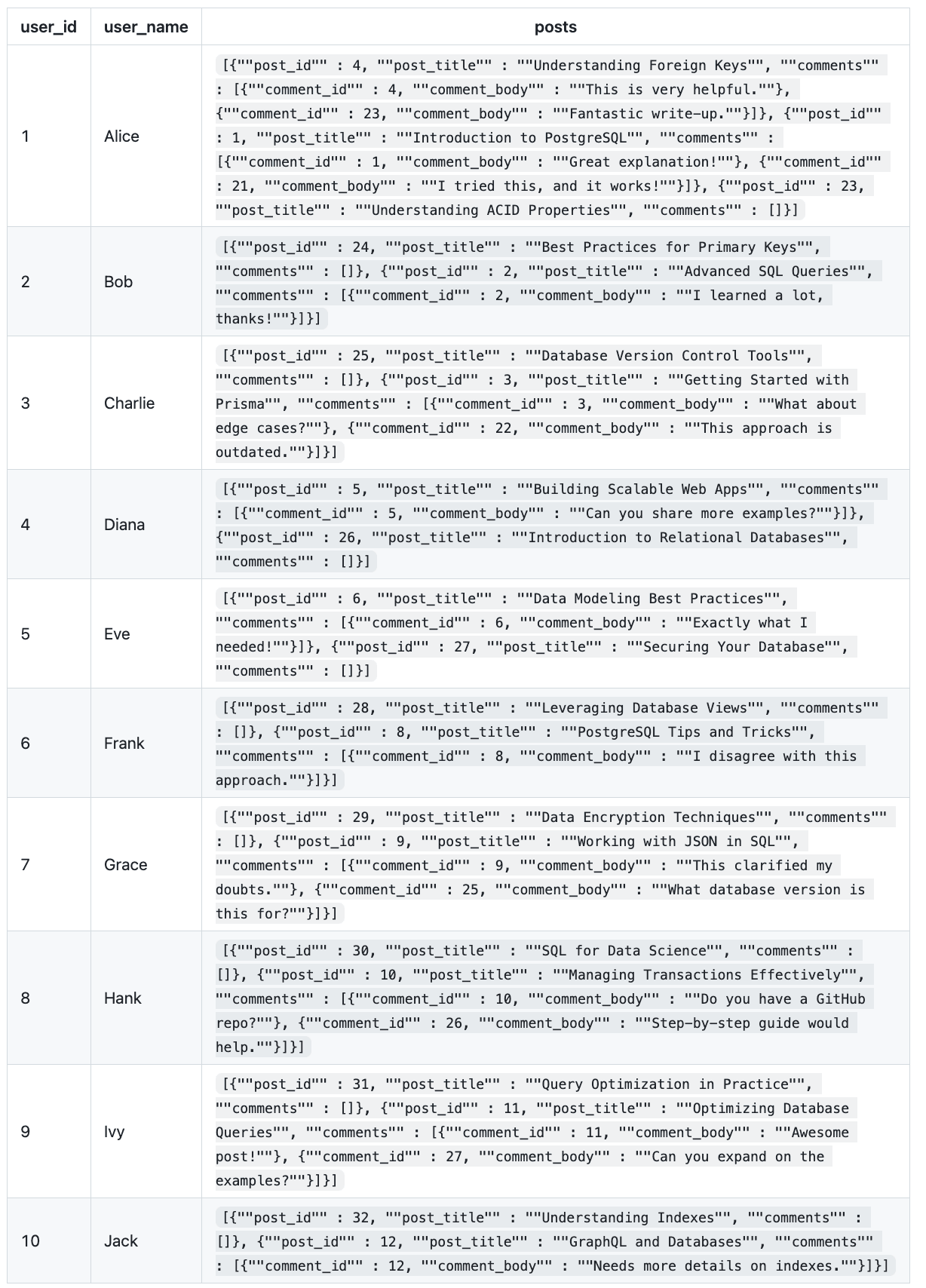
这些数据与关于朴素数据库级连接部分的相似,不同之处在于
- 它不再包含冗余
- 帖子已以 JSON 结构格式化
虽然这个查询可能比朴素策略产生格式更好的结果,但它也变得冗长和复杂。请记住,我们仍在讨论一个相对简单的整体场景:连接三个表,而没有大多数实际应用程序所处理的额外因素(例如过滤和分页)。
Prisma ORM 中 JOIN 策略的演进
当 Prisma ORM 于2021 年首次发布时,它对其所有关系查询都实现了应用程序级连接策略。
当应用服务器和数据库彼此靠近时,这种策略非常有效,有助于跨数据库引擎的可移植性,并提高整个系统的可扩展性(因为应用程序层的 CPU 比数据库层的 CPU 更容易且成本更低)。
尽管应用程序级连接方法对大多数开发人员都很有用,但当应用程序服务器和数据库无法彼此靠近托管时,有时会导致问题,并且额外的往返会负面影响整体查询性能。
这就是为什么我们在一年前添加了智能数据库级连接作为替代方案,这样开发人员就可以选择最适合其特定用例的连接策略。
能够使用数据库级连接一直是 Prisma ORM 最受欢迎的功能请求之一,并且自发布预览版以来一直受到我们社区的好评。一旦此功能普遍可用,数据库级连接将成为 Prisma ORM 用于其关系查询的默认连接策略。
社区反馈是帮助我们优先处理 Prisma ORM 改进工作的主要驱动力之一。
结论
找出从数据库中连接多个表数据最高效的方法是一个复杂的话题。在本文中,我们探讨了三种不同的方法:数据库层面的朴素连接和智能连接,以及应用程序级连接。
朴素的数据库级连接会给数据库服务器带来高 CPU 成本,并因不必要地传输冗余数据而导致网络开销。
应用程序级连接因其简单性以及在数据库层面执行成本低廉,可能更适合许多场景。使用此策略的系统通常也更容易且成本更低地进行扩展。
最后,智能数据库级连接解决了冗余问题,可以返回为应用程序开发人员量身定制的嵌套结构数据,并且总体上更有可能被数据库引擎更好地优化。
不要错过下一篇文章!
订阅 Prisma 新闻邮件