Prisma ORM 是 ORM 吗?
简短回答:是的,Prisma ORM 是一种新型 ORM,它与传统 ORM 根本不同,并且没有许多与传统 ORM 相关联的常见问题。
传统 ORM 通过将表映射到编程语言中的模型类,提供了一种面向对象的方式来处理关系数据库。这种方法导致了许多问题,这些问题是由对象关系阻抗失配引起的。
Prisma ORM 的工作方式与此根本不同。使用 Prisma ORM,您可以在声明性的Prisma 模式中定义模型,该模式作为数据库模式和编程语言中模型的单一事实来源。在应用程序代码中,您可以使用 Prisma Client 以类型安全的方式读取和写入数据库中的数据,而无需管理复杂模型实例的开销。这使得查询数据过程更加自然和可预测,因为 Prisma Client 总是返回纯 JavaScript 对象。
在本文中,您将更详细地了解 ORM 模式和工作流、Prisma ORM 如何实现数据映射器模式以及 Prisma ORM 方法的优势。
什么是 ORM?
如果您已经熟悉 ORM,请随意跳到有关 Prisma ORM 的下一部分。
ORM 模式 - Active Record 和 Data Mapper
ORM 提供了一个高级数据库抽象。它们通过对象公开一个编程接口,用于创建、读取、删除和操作数据,同时隐藏了数据库的一些复杂性。
ORM 的思想是,您将模型定义为类,这些类映射到数据库中的表。这些类及其实例为您提供了一个编程 API,用于在数据库中读取和写入数据。
有两种常见的 ORM 模式:Active Record 和 Data Mapper,它们在数据在对象和数据库之间传输的方式上有所不同。虽然这两种模式都要求您将类定义为主要构建块,但两者之间最显著的区别是,数据映射器模式将应用程序代码中的内存对象与数据库分离,并使用数据映射器层在两者之间传输数据。实际上,这意味着使用数据映射器时,内存对象(表示数据库中的数据)甚至不知道数据库的存在。
Active Record
Active Record ORM 将模型类映射到数据库表,其中两种表示的结构密切相关,例如,模型类中的每个字段都将在数据库表中有一个匹配的列。模型类的实例包装数据库行,并携带数据和访问逻辑以处理数据库中持久化更改。此外,模型类可以携带特定于模型中数据的业务逻辑。
模型类通常具有执行以下操作的方法
- 从 SQL 查询构建模型的实例。
- 构建新实例以供稍后插入表中。
- 包装常用的 SQL 查询并返回 Active Record 对象。
- 更新数据库并将 Active Record 中的数据插入其中。
- 获取和设置字段。
- 实现业务逻辑。
数据映射器
与 Active Record 相比,数据映射器 ORM 将应用程序内存中的数据表示与数据库的表示分离。这种分离是通过要求您将映射职责分为两种类型的类来实现的
- 实体类:应用程序内存中的实体表示,它们对数据库一无所知
- 映射器类:它们有两个职责
- 在两种表示之间转换数据。
- 生成从数据库中获取数据并持久化数据库中更改所需的 SQL。
数据映射器 ORM 允许在代码中实现的问题域与数据库之间有更大的灵活性。这是因为数据映射器模式允许您隐藏数据库的实现方式,这并不是一种理想的思考整个数据映射层背后的领域的方式。
传统数据映射器 ORM 这样做的一个原因是由于组织结构,其中这两个职责将由不同的团队处理,例如,DBA 和后端开发人员。
实际上,并非所有数据映射器 ORM 都严格遵守此模式。例如,TypeScript 生态系统中流行的支持 Active Record 和数据映射器的 ORM TypeORM,对数据映射器采取以下方法
- 实体类使用装饰器 (
@Column) 将类属性映射到表列并了解数据库。 - 不使用映射器类,而是使用存储库类来查询数据库,并且可能包含自定义查询。存储库使用装饰器来确定实体属性和数据库列之间的映射。
给定数据库中的以下 User 表

这是相应的实体类看起来的样子
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm'
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ name: 'first_name' })
firstName: string
@Column({ name: 'last_name' })
lastName: string
@Column({ unique: true })
email: string
}
模式迁移工作流
开发利用数据库的应用程序的一个核心部分是更改数据库模式以适应新功能并更好地适应您正在解决的问题。在本节中,我们将讨论模式迁移是什么以及它们如何影响工作流。
因为 ORM 位于开发人员和数据库之间,所以大多数 ORM 提供了一个迁移工具来帮助创建和修改数据库模式。
迁移是一组步骤,用于将数据库模式从一种状态转换为另一种状态。第一次迁移通常创建表和索引。后续迁移可能会添加或删除列、引入新索引或创建新表。根据迁移工具,迁移可能是 SQL 语句的形式或将被转换为 SQL 语句的程序代码(如 ActiveRecord 和 SQLAlchemy)。
因为数据库通常包含数据,所以迁移有助于您将模式更改分解为更小的单元,这有助于避免意外数据丢失。
假设您从头开始一个项目,完整的工作流将是:您创建一个迁移,将在数据库模式中创建 User 表,并如上例所示定义 User 实体类。
然后,随着项目的进展,您决定要向 User 表添加一个新 salutation 列,您将创建另一个迁移,它将更改表并添加 salutation 列。
让我们看看 TypeORM 迁移会是什么样子
import { MigrationInterface, QueryRunner } from 'typeorm'
export class UserRefactoring1604448000 implements MigrationInterface {
async up(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query(`ALTER TABLE "User" ADD COLUMN "salutation" TEXT`)
}
async down(queryRunner: QueryRunner): Promise<void> {
await queryRunner.query(`ALTER TABLE "User" DROP COLUMN "salutation"`)
}
}
一旦执行迁移并且数据库模式已更改,实体和映射器类也必须更新以考虑新的 salutation 列。
使用 TypeORM,这意味着将 salutation 属性添加到 User 实体类
import { Entity, PrimaryGeneratedColumn, Column } from 'typeorm'
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number
@Column({ name: 'first_name' })
firstName: string
@Column({ name: 'last_name' })
lastName: string
@Column({ unique: true })
email: string
@Column()
salutation: string
}
使用 ORM 同步此类更改可能是一个挑战,因为更改是手动应用的,并且不容易以编程方式验证。重命名现有列可能更麻烦,并且涉及搜索和替换对该列的引用。
注意: Django 的 makemigrations CLI 通过检查模型中的更改来生成迁移,这与 Prisma ORM 类似,消除了同步问题。
总之,演化模式是构建应用程序的关键部分。使用 ORM,更新模式的工作流涉及使用迁移工具创建迁移,然后更新相应的实体和映射器类(取决于实现)。正如您将看到的,Prisma ORM 对此采取了不同的方法。
现在您已经了解了迁移是什么以及它们如何适应开发工作流,您将了解 ORM 的优点和缺点。
ORM 的好处
开发人员选择使用 ORM 有不同的原因
- ORM 促进了领域模型的实现。领域模型是一个对象模型,它包含了业务逻辑的行为和数据。换句话说,它允许您专注于真实的业务概念,而不是数据库结构或 SQL 语义。
- ORM 有助于减少代码量。它们使您无需为常见的 CRUD(创建、读取、更新、删除)操作编写重复的 SQL 语句,也无需转义用户输入以防止 SQL 注入等漏洞。
- ORM 要求您编写很少甚至不编写 SQL(取决于您的复杂性,您可能仍需要编写一些原始查询)。这对于不熟悉 SQL 但仍想使用数据库的开发人员很有益。
- 许多 ORM 抽象了数据库特定的细节。理论上,这意味着 ORM 可以使从一个数据库更改到另一个数据库更容易。应该注意的是,在实践中,应用程序很少更改它们使用的数据库。
与所有旨在提高生产力的抽象一样,使用 ORM 也有缺点。
ORM 的缺点
当您开始使用 ORM 时,它们的缺点并不总是很明显。本节介绍了一些普遍接受的缺点
- 使用 ORM,您形成数据库表的对象图表示,这可能导致对象关系阻抗失配。当您正在解决的问题形成一个复杂的对象图,而该对象图不能简单地映射到关系数据库时,就会发生这种情况。在数据的两种不同表示之间进行同步,一种在关系数据库中,另一种在内存中(使用对象)是相当困难的。这是因为与关系数据库记录相比,对象在相互关联的方式上更灵活、更多样化。
- 虽然 ORM 处理与问题相关的复杂性,但同步问题并没有消失。对数据库模式或数据模型的任何更改都需要将更改映射回另一方。这种负担通常落在开发人员身上。在团队处理项目的情况下,数据库模式更改需要协调。
- 由于 ORM 封装的复杂性,它们往往具有很大的 API 表面。不编写 SQL 的另一面是您花费大量时间学习如何使用 ORM。这适用于大多数抽象,但是如果不了解数据库的工作原理,改进慢速查询可能会很困难。
- 由于 SQL 提供的灵活性,某些复杂查询不受 ORM 支持。通过原始 SQL 查询功能可以缓解此问题,在该功能中,您将 SQL 语句字符串传递给 ORM,并为您运行查询。
现在已经介绍了 ORM 的成本和收益,您可以更好地理解 Prisma ORM 是什么以及它如何适应。
Prisma ORM
Prisma ORM 是下一代 ORM,它使应用程序开发人员轻松使用数据库,并具有以下工具
- Prisma Client:自动生成且类型安全的数据库客户端,用于您的应用程序。
- Prisma Migrate:一个声明式数据建模和迁移工具。
- Prisma Studio:一个现代 GUI,用于浏览和管理数据库中的数据。
注意:由于 Prisma Client 是最突出的工具,我们通常将其简称为 Prisma。
这三个工具都使用Prisma 模式作为数据库模式、应用程序对象模式以及两者之间映射的单一事实来源。它由您定义,是您配置 Prisma ORM 的主要方式。
Prisma ORM 通过类型安全、丰富的自动补全和自然的 API 来获取关系等功能,使您在构建软件时高效自信。
在下一节中,您将了解 Prisma ORM 如何实现数据映射器 ORM 模式。
Prisma ORM 如何实现数据映射器模式
如文章前面所述,数据映射器模式与数据库和应用程序由不同团队拥有的组织非常契合。
随着现代云环境和托管数据库服务以及 DevOps 实践的兴起,越来越多的团队采用跨职能方法,即团队拥有包括数据库和操作关注点在内的完整开发周期。
Prisma ORM 实现了数据库模式和对象模式的同步演进,从而减少了首先需要偏差,同时仍然允许您使用 @map 属性使应用程序和数据库在某种程度上解耦。虽然这可能看起来像一个限制,但它阻止了领域模型演进(通过对象模式)作为事后思考强加给数据库。
为了理解 Prisma ORM 对数据映射器模式的实现与传统数据映射器 ORM 在概念上有何不同,这里是它们的概念和构建块的简要比较
| 概念 | 描述 | 传统 ORM 中的构建块 | Prisma ORM 中的构建块 | Prisma ORM 中的事实来源 |
|---|---|---|---|---|
| 对象模式 | 应用程序中的内存数据结构 | 模型类 | 生成的 TypeScript 类型 | Prisma 模式中的模型 |
| 数据映射器 | 在对象模式和数据库之间进行转换的代码 | 映射器类 | Prisma Client 中生成的函数 | Prisma 模式中的 @map 属性 |
| 数据库模式 | 数据库中数据的结构,例如表和列 | 手动编写或使用编程 API 编写的 SQL | Prisma Migrate 生成的 SQL | Prisma schema |
Prisma ORM 与数据映射器模式保持一致,并具有以下额外优势
- 通过基于 Prisma 模式生成 Prisma Client 来减少定义类和映射逻辑的样板文件。
- 消除应用程序对象和数据库模式之间的同步挑战。
- 数据库迁移是一等公民,因为它们源自 Prisma 模式。
现在我们已经讨论了 Prisma ORM 数据映射器方法的概念,我们可以了解 Prisma 模式在实践中是如何工作的。
Prisma 模式
Prisma 实现数据映射器模式的核心是Prisma 模式——以下职责的单一事实来源
- 配置 Prisma 如何连接到数据库。
- 生成 Prisma Client – 应用程序代码中使用的类型安全 ORM。
- 使用 Prisma Migrate 创建和演进数据库模式。
- 定义应用程序对象和数据库列之间的映射。
Prisma ORM 中的模型与 Active Record ORM 中的模型略有不同。在 Prisma ORM 中,模型在 Prisma 模式中定义为抽象实体,它们描述了表、关系以及 Prisma Client 中列到属性的映射。
例如,这是一个博客的 Prisma 模式
datasource db {
provider = "postgresql"
}
generator client {
provider = "prisma-client"
output = "./generated"
}
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
以下是上面示例的分解
datasource块定义了与数据库的连接。generator块告诉 Prisma ORM 为 TypeScript 和 Node.js 生成 Prisma Client。Post和User模型映射到数据库表。- 这两个模型有一个1-n关系,其中每个
User可以有多个相关的Post。 - 模型中的每个字段都有一个类型,例如,
id具有类型Int。 - 字段可能包含字段属性以定义
- 使用
@id属性定义主键。 - 使用
@unique属性定义唯一键。 - 使用
@default属性定义默认值。 - 使用
@map属性在表列和 Prisma Client 字段之间进行映射,例如,content字段(将在 Prisma Client 中可访问)映射到post_content数据库列。
- 使用
User / Post 关系可以用以下图表可视化
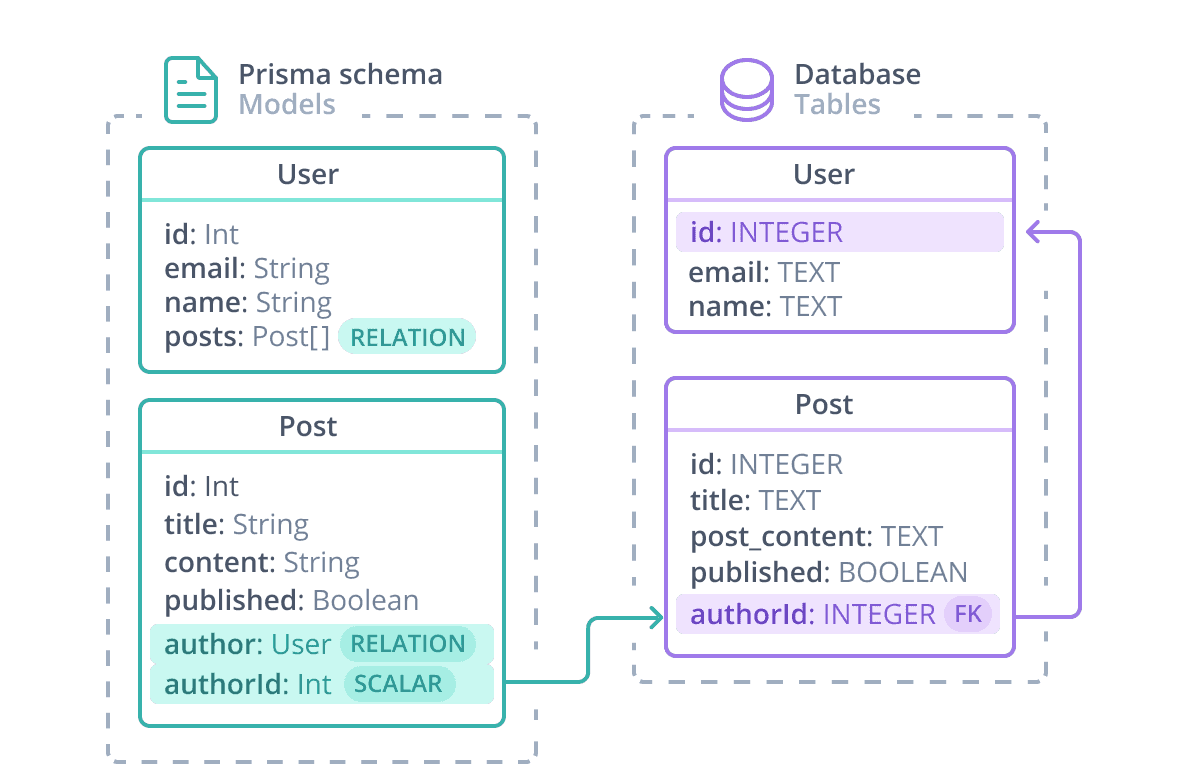
在 Prisma ORM 级别,User / Post 关系由以下组成
- 标量
authorId字段,由@relation属性引用。此字段存在于数据库表中——它是连接 Post 和 User 的外键。 - 两个关系字段:
author和posts不存在于数据库表中。关系字段在 Prisma ORM 级别定义模型之间的连接,并且仅存在于 Prisma 模式和生成的 Prisma Client 中,用于访问关系。
Prisma 模式的声明性特性简洁,允许定义数据库模式和 Prisma Client 中的相应表示。
在下一节中,您将了解 Prisma ORM 支持的工作流。
Prisma ORM工作流
Prisma ORM 的工作流与传统 ORM 略有不同。您可以在从头开始构建新应用程序时使用 Prisma ORM,或逐步采用它
- 新应用程序(绿地):尚未拥有数据库模式的项目可以使用 Prisma Migrate 创建数据库模式。
- 现有应用程序(棕地):已经拥有数据库模式的项目可以通过 Prisma ORM 内省以生成 Prisma 模式和 Prisma Client。此用例适用于任何现有迁移工具,对于增量采用很有用。可以切换到 Prisma Migrate 作为迁移工具。但是,这是可选的。
在这两种工作流中,Prisma 模式都是主要的配置文件。
具有现有数据库的项目中增量采用的工作流
棕地项目通常已经有一些数据库抽象和模式。Prisma ORM 可以通过内省现有数据库来集成此类项目,以获取反映现有数据库模式的 Prisma 模式并生成 Prisma Client。此工作流与您可能已经使用的任何迁移工具和 ORM 兼容。如果您更喜欢逐步评估和采用,此方法可以用作并行采用策略的一部分。
与此工作流兼容的非详尽设置列表
- 使用带有
CREATE TABLE和ALTER TABLE的纯 SQL 文件来创建和更改数据库模式的项目。 - 使用第三方迁移库(如 db-migrate 或 Umzug)的项目。
- 已经使用 ORM 的项目。在这种情况下,通过 ORM 的数据库访问保持不变,而生成的 Prisma Client 可以增量采用。
实际上,内省现有数据库并生成 Prisma Client 所需的步骤是
- 创建一个定义
datasource(在此例中为您的现有数据库)和generator的schema.prisma
datasource db {
provider = "postgresql"
url = "postgresql://janedoe:janedoe@localhost:5432/hello-prisma"
}
generator client {
provider = "prisma-client"
output = "./generated"
}
- 运行
prisma db pull,使用从数据库模式派生的模型填充 Prisma 模式。 - (可选)自定义 Prisma Client 和数据库之间的字段和模型映射。
- 运行
prisma generate。
Prisma ORM 将在 node_modules 文件夹中生成 Prisma Client,您可以从该文件夹将其导入到应用程序中。有关更广泛的使用文档,请参阅 Prisma Client API 文档。
总而言之,Prisma Client 可以作为并行采用策略的一部分集成到具有现有数据库和工具的项目中。新项目将使用下一步详细介绍的不同工作流。
新项目的工作流
Prisma ORM 在其支持的工作流方面与 ORM 不同。仔细查看创建和更改新数据库模式所需的步骤有助于理解 Prisma Migrate。
Prisma Migrate 是一个用于声明式数据建模和迁移的 CLI。与大多数作为 ORM 一部分的迁移工具不同,您只需要描述当前模式,而不是从一种状态到另一种状态的操作。Prisma Migrate 推断操作,生成 SQL 并为您执行迁移。
此示例演示了如何在具有新数据库模式的新项目中使用 Prisma ORM,类似于上面的博客示例
- 创建 Prisma 模式
// schema.prisma
datasource db {
provider = "postgresql"
url = "postgresql://janedoe:janedoe@localhost:5432/hello-prisma"
}
generator client {
provider = "prisma-client"
output = "./generated"
}
model Post {
id Int @id @default(autoincrement())
title String
content String? @map("post_content")
published Boolean @default(false)
author User? @relation(fields: [authorId], references: [id])
authorId Int?
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
- 运行
prisma migrate以生成迁移的 SQL,将其应用于数据库,并生成 Prisma Client。
对于数据库模式的任何进一步更改
- 将更改应用于 Prisma 模式,例如,向
User模型添加registrationDate字段 - 再次运行
prisma migrate。
最后一步演示了声明式迁移如何通过向 Prisma 模式添加字段并使用 Prisma Migrate 将数据库模式转换为所需状态来工作。运行迁移后,Prisma Client 会自动重新生成,以反映更新的模式。
如果您不想使用 Prisma Migrate 但仍想在新项目中使用类型安全的生成的 Prisma Client,请参阅下一节。
没有 Prisma Migrate 的新项目的替代方案
可以在新项目中使用 Prisma Client,并使用第三方迁移工具而不是 Prisma Migrate。例如,新项目可以选择使用 Node.js 迁移框架 db-migrate 来创建数据库模式和迁移,并使用 Prisma Client 进行查询。本质上,这已包含在现有数据库的工作流中。
使用 Prisma Client 访问数据
到目前为止,本文介绍了 Prisma ORM 背后的概念、其数据映射器模式的实现以及它支持的工作流。在最后一节中,您将了解如何使用 Prisma Client 访问应用程序中的数据。
使用 Prisma Client 访问数据库是通过其公开的查询方法进行的。所有查询都返回普通的 JavaScript 对象。给定上面的博客模式,获取用户如下所示
import { PrismaClient } from '../prisma/generated/client'
const prisma = new PrismaClient()
const user = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
})
在此查询中,findUnique() 方法用于从 User 表中获取单行。默认情况下,Prisma ORM 将返回 User 表中的所有标量字段。
注意:该示例使用 TypeScript 以充分利用 Prisma Client 提供的类型安全功能。但是,Prisma ORM 也适用于 Node.js 中的 JavaScript。
Prisma Client 通过从 Prisma 模式生成代码将查询和结果映射到结构类型。这意味着 user 在生成的 Prisma Client 中具有关联的类型
export type User = {
id: number
email: string
name: string | null
}
这确保了访问不存在的字段将引发类型错误。更广泛地说,这意味着每个查询的结果类型在运行查询之前都是已知的,这有助于捕获错误。例如,以下代码片段将引发类型错误
console.log(user.lastName) // Property 'lastName' does not exist on type 'User'.
获取关系
使用 include 选项获取 Prisma Client 中的关系。例如,要获取用户及其帖子,可以按如下方式完成
const user = await prisma.user.findUnique({
where: {
email: 'alice@prisma.io',
},
include: {
posts: true,
},
})
使用此查询,user 的类型也将包括 Post,可以通过 posts 数组字段访问
console.log(user.posts[0].title)
该示例仅触及 Prisma Client 用于CRUD 操作的 API 的皮毛,您可以在文档中了解更多信息。主要思想是所有查询和结果都由类型支持,并且您可以完全控制如何获取关系。
结论
总而言之,Prisma ORM 是一种新型的数据映射器 ORM,它与传统 ORM 不同,并且不会遭受与传统 ORM 相关联的常见问题。
与传统 ORM 不同,使用 Prisma ORM,您定义 Prisma 模式——数据库模式和应用程序模型的声明性单一事实来源。Prisma Client 中的所有查询都返回普通的 JavaScript 对象,这使得与数据库交互的过程更加自然和可预测。
Prisma ORM 支持两种主要工作流,用于启动新项目和在现有项目中采用。对于这两种工作流,您的主要配置途径是通过 Prisma 模式。
与所有抽象一样,Prisma ORM 和其他 ORM 都以不同的假设隐藏了数据库的一些底层细节。
这些差异和您的用例都会影响工作流和采用成本。希望了解它们之间的差异可以帮助您做出明智的决定。